


A. Tổng quan về Spark
Apache Spark là một hệ thống tính toán phân tán, mã nguồn mở được thiết kế để xử lý dữ liệu lớn. Spark thường được sử dụng với mục đích phân tích dữ liệu lớn(Data Pipeline, Machine learning, real-time data processing…). Để nói về Spark, ta có thể tóm gọm nó trong 4 cụm từ: Nhanh – Dễ sử dụng – Linh hoạt – Dễ dàng mở rộng
B. Kiến trúc của Spark

Hình 1: Kiến trúc của Spark
Master Node trong Kiến Trúc Spark
Master Node là thành phần trung tâm và rất quan trọng trong Spark. Nó là nơi nhận yêu cầu từ người dùng, lên kế hoạch thực thi các Tasks và phân phối các Tasks đến các Worker Node. Master Node như một “người quản lý” đóng vai trò điều phối toàn bộ quá trình, Từ việc quản lý các tài nguyên tới theo dõi trạng thái của các Executor
Thành phần quan trọng nhất trong Master Node chính là Driver Program. Nó là thành phần quan trọng nhất trong Master Node vì:
- Driver sẽ chuyển đổi mã nguồn của người dùng thành các kế hoạch thực thi dưới dạng DAG (Sẽ có một phần riêng nói về dạng DAG này)
- Khi bạn viết code, Driver sẽ chuyển các đoạn code này thành các Stages và Tasks, sau đó phân phối chúng tới các Worker Node để thực thi.
- Sau khi các Worker Node đã hoàn thành công việc của mình, Master Node sẽ thu thập kết quả từ các Worker Node. Dữ liệu kết quả này sau đó sẽ được hợp nhất và trả về cho người dùng hoặc lưu vào hệ thống lưu trữ ngoài (như HDFS, S3, Lakehouse…)
Cluster Manager
Cluster Manager là thành phần chịu trách nhiệm quản lý và phân bổ tài nguyên trong Spark cluster. Các tài nguyên này bao gồm CPU và memory, và Cluster Manager sẽ phân phối chúng cho các thành phần khác của Spark là Driver và Executors. Mục tiêu là đảm bảo rằng các tasks được thực thi một cách hiệu quả và không xảy ra tình trạng thiếu tài nguyên hay xung đột
Apache Spark hỗ trợ nhiều loại Cluster Manager khác nhau nhưng tiêu biểu của Cluster Manager có thể kể đến đó chính là Standalone Cluster Manager. Đây là Cluster Manager tích hợp sẵn trong Spark. Khi sử dụng Standalone, Spark tự quản lý tài nguyên mà không cần phần mềm quản lý bên ngoài. Đây là lựa chọn đơn giản và dễ sử dụng cho các trường hợp không yêu cầu một cluster phức tạp
Nhiệm Vụ của Cluster Manager: Một trong những thách thức trong môi trường tính toán phân tán là xung đột tài nguyên giữa các tasks. Cluster Manager chịu trách nhiệm phân phối tài nguyên (như CPU và memory) từ các Worker Nodes cho Driver và Executors. Điều này giúp đảm bảo rằng các tasks có đủ tài nguyên để thực thi mà không bị gián đoạn
Worker Node trong Spark là các node trong cluster chịu trách nhiệm thực thi các công việc tính toán. Các công việc này chính là các Tasks — những đơn vị công việc nhỏ được Driver Program lên lịch và phân phối đến các Executor trên các Worker Node để thực hiện
Thành phần của Worker Node
Executor: Executor là thành phần chính trong Worker Node, chịu trách nhiệm thực thi các Tasks. Mỗi Executor có thể thực thi nhiều Tasks đồng thời, tùy thuộc vào tài nguyên (CPU, memory) mà nó có. Executor cũng lưu trữ dữ liệu trong bộ nhớ (in-memory) hoặc trên đĩa (disk), phụ thuộc vào yêu cầu của Task. Dữ liệu này có thể bao gồm các kết quả tính toán hoặc dữ liệu cần thiết cho các bước tính toán tiếp theo
Job: Job là một đơn vị công việc lớn, tương ứng với một hành động (action) mà bạn thực hiện trên DataFrame hoặc RDD. Một ứng dụng Spark có thể có nhiều Job
Stage: Stage là một bước trong quá trình thực thi của một Job. Một Job có thể được chia thành nhiều Stage. Các Stage được phân tách bởi các thao tác shuffle
Task: Task là đơn vị công việc nhỏ nhất trong Spark. Mỗi Task được gửi từ Driver Program đến Executor để thực thi. Các Tasks này được phân chia từ các công việc lớn hơn, như các phần của một DataFrame hay RDD, và có thể được thực thi song song trên các Worker Node khác nhau
Nhiệm vụ của Worker Node
- Thực thi các Tasks: Worker Node chịu trách nhiệm thực thi các Tasks mà Driver Program đã lên lịch. Các Tasks này có thể bao gồm các bước tính toán dữ liệu, thao tác với các RDD, hay thực hiện các phép toán trên DataFrame
- Lưu trữ dữ liệu: Kết quả của các Tasks có thể được lưu trong bộ nhớ (in-memory) hoặc trên đĩa (disk) của Executor, tùy thuộc vào yêu cầu của các Tasks và lượng tài nguyên sẵn có. Spark thường ưu tiên lưu trữ dữ liệu trong bộ nhớ để tăng tốc độ xử lý, nhưng nếu bộ nhớ không đủ, dữ liệu sẽ được lưu trữ trên đĩa.
- Giao tiếp với Driver Program: Sau khi thực hiện xong các Tasks, Executor sẽ báo cáo trạng thái của Tasks (thành công hoặc thất bại) và gửi kết quả về Driver Program. Điều này giúp Driver nắm được tiến độ và kết quả của các công việc
C. Spark Trong Microsoft Fabric
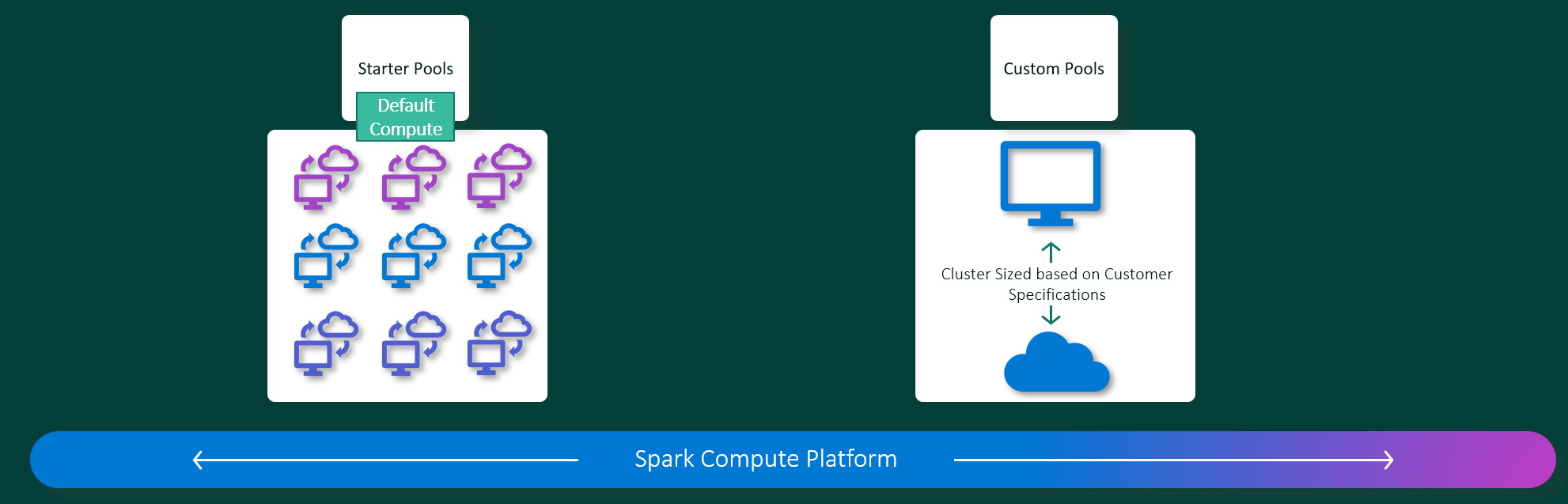
Spark Pool
Giống như cái nền tảng SSAS thì Spark trong Fabric được cung cấp dưới dạng một dịch vụ được quản lý hoàn toàn (fully managed service). Điều này có nghĩa là bạn không cần lo lắng về việc thiết lập, cấu hình hay quản lý các cluster Spark. Fabric sẽ lo tất cả các công việc này cho bạn. Khi sử dụng Spark trên Microsoft Fabric thì ta sẽ cần biết thêm một khái niệm nữa đó chính là Spark Pool. Spark Pool là một nhóm các thiết lập cấu hình trước được sử dụng để xác định tài nguyên (Memory, CPU và nodes) mà Spark sẽ sử dụng để chạy các tác vụ phân tán. Nói một cách đơn giản, Spark Pool giống như một container chứa các thông số cấu hình mà Spark sẽ sử dụng để thực hiện các công việc xử lý dữ liệu
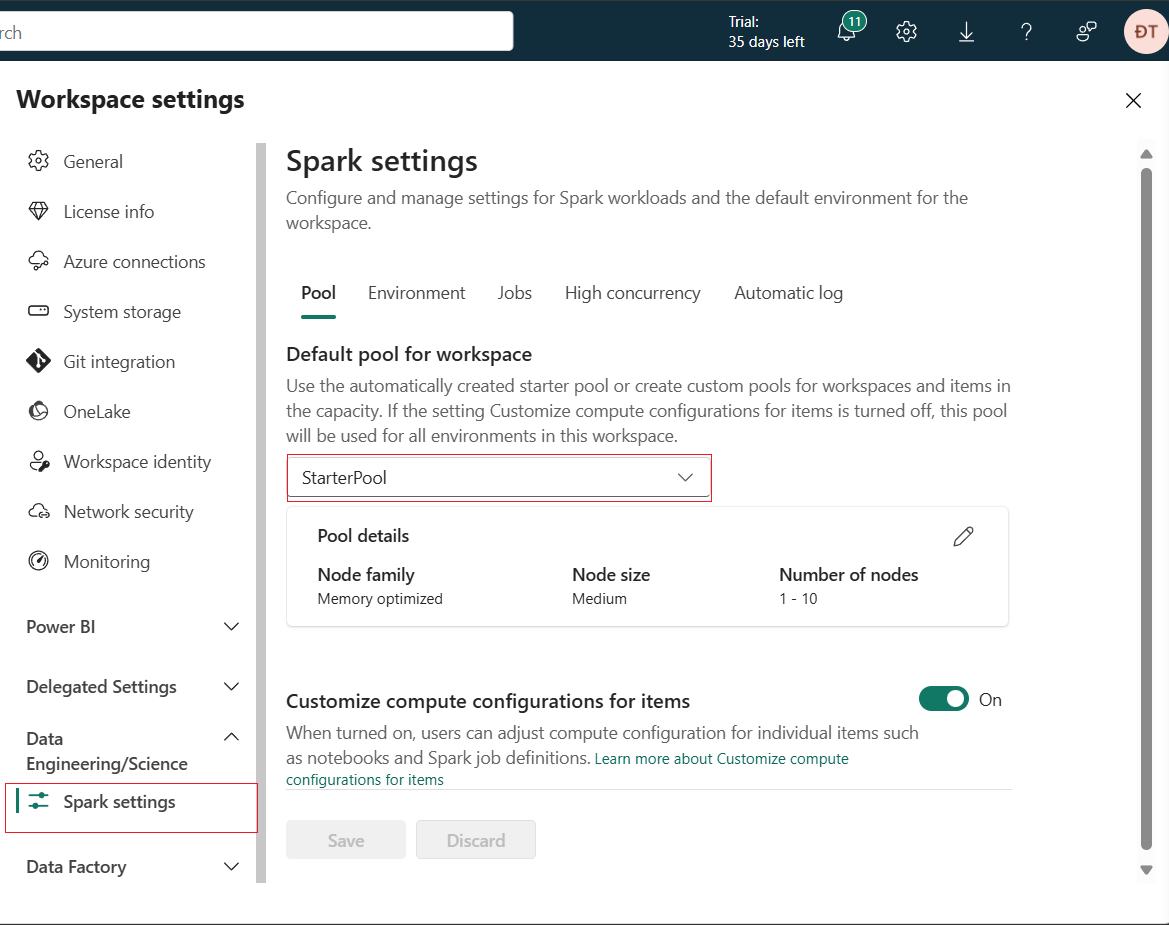
Hình 2: Cấu hình Spark pool
Các loại Spark Pool:
- Starter Pool: Dành cho người dùng mới hoặc không rành về cấu hình Spark. Nó được cấu hình tự động với các thiết lập cơ bản phù hợp cho các tác vụ thông thường. Đây là lựa chọn phù hợp cho các công việc nhỏ hoặc những người mới bắt đầu.
- Custom Pool: Dành cho những người dùng có kinh nghiệm và yêu cầu cấu hình cụ thể cho các công việc phức tạp. Custom Pool cho phép người dùng tùy chỉnh các tham số cấu hình của pool để phù hợp với từng dự án cụ thể
Việc cấu hình Spark pool cho WorkSpace có thể được thực hiện trong mục Workspace settings 🡪 Data Engineering/Science 🡪 Pool
Demo chạy Spark bằng Notebook trong Microsoft Fabric
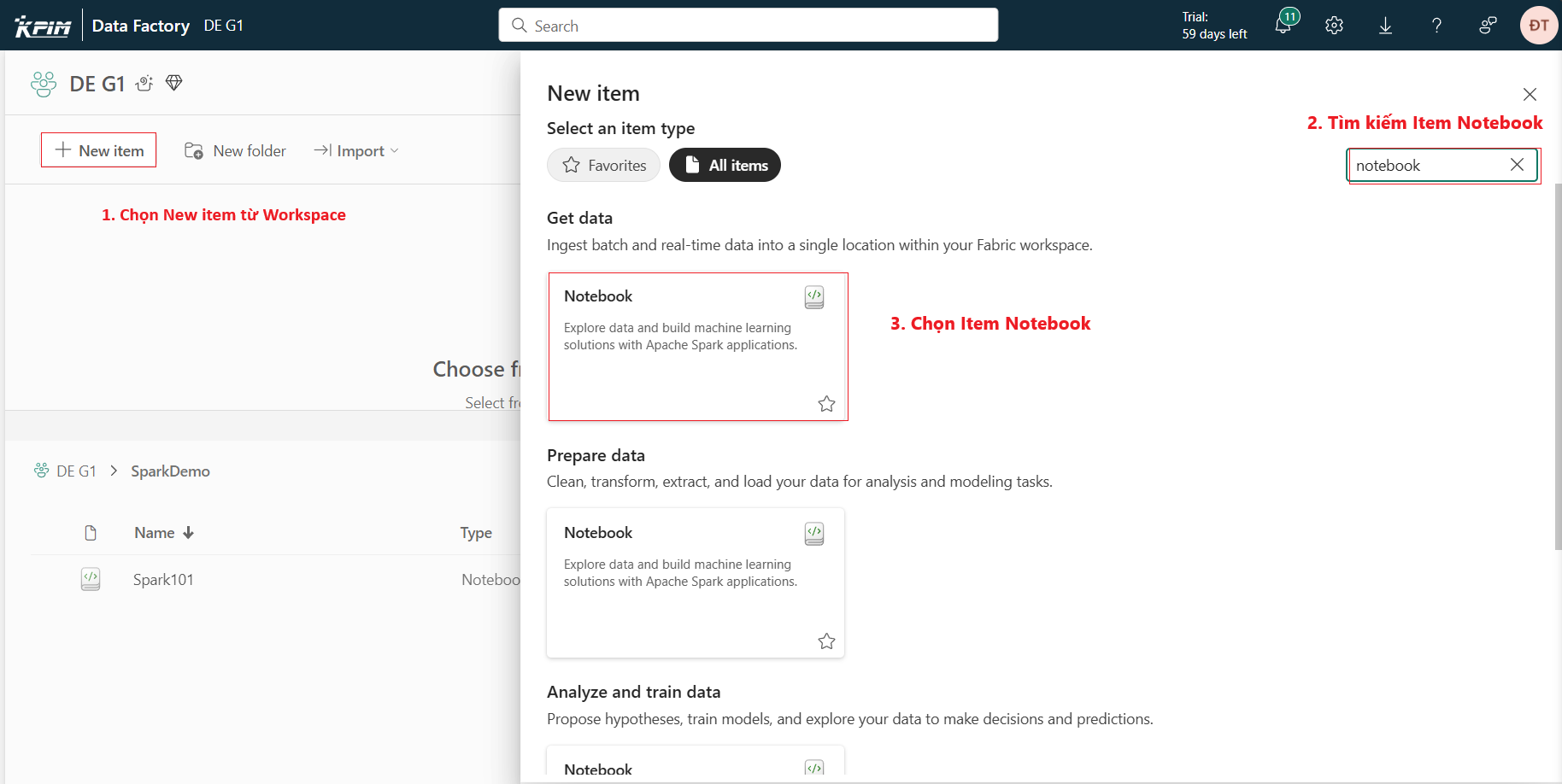
Trước tiên ta cần tạo Notebook trong Workspace bằng cách thực hiện các bước sau đây:
-
- Chọn Workspace: Truy cập vào Workspace nơi bạn muốn tạo Notebook( Workspace là không gian làm việc chứa các tài nguyên như datasets, pipelines, reports và notebooks)
- Tạo mới một mục (New Item):Tại giao diện chính của Workspace, nhấp vào nút “New Item” nằm ở góc trên bên trái. Thao tác này sẽ mở ra cửa sổ danh sách các item có thể tạo mới.
- Tìm và chọn Notebook:Trong ô tìm kiếm hoặc danh sách các mục, gõ hoặc cuộn để tìm “Notebook”. Khi mục Notebook hiện ra, nhấp chọn item này để bắt đầu tạo mới
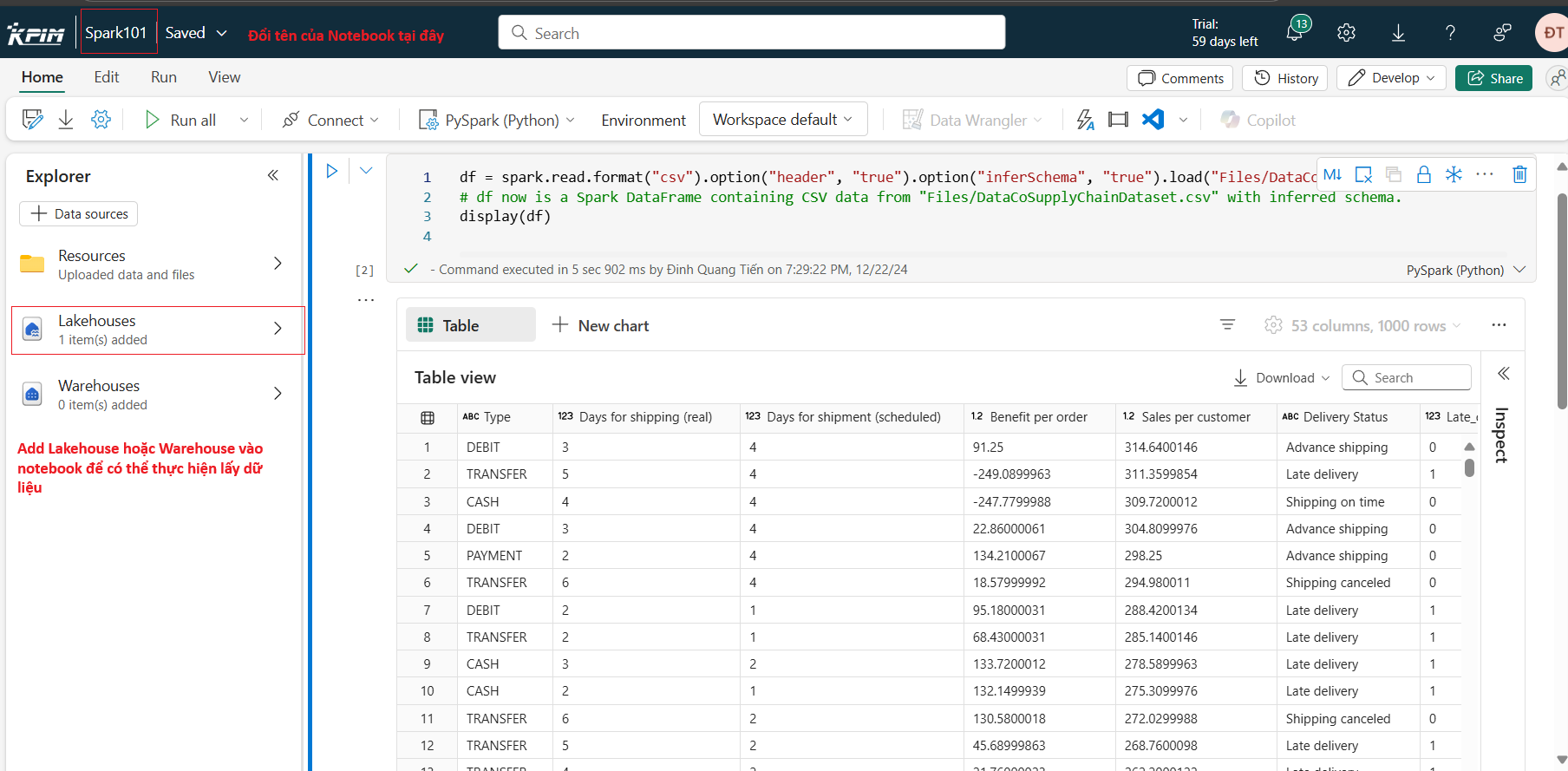
Sau khi đã tạo Notebook, tại giao diện của notebook ta cần thực hiện thêm lakehouse hoặc warehouse mà ta muốn lấy dữ liệu bằng cách:
- Tại cửa sổ Explorer ta chọn biểu tượng Lakehouses(Warehouses)
- Chọn Lakehouse(Warehouse) mà ta muốn thêm vào notebook, khi thấy số lượng item thay đổi từ 0 sang 1 thì lakehouse(warehouse) đã được thêm thành công
Viết bài: Đinh Quang Tiến





