


Microsoft Fabric là nền tảng dữ liệu mới nhất của Microsoft, cung cấp nhiều tính năng mạnh mẽ giúp các doanh nghiệp dễ dàng thu thập, lưu trữ, quản trị, phân tích, khai thác dữ liệu hiệu quả. Phiên bản thử nghiệm của Fabric ra mắt từ tháng 5 năm 2023.
Đến thời điểm hiện tại, Microsoft Fabric đã hoạt động ổn định hơn rất nhiều, đồng thời cung cấp chính thức một số chính sách giá, từ đó hứa hẹn là một giải pháp quản trị & phân tích dữ liệu toàn diện để các doanh nghiệp triển khai trong năm 2024 này.
Trong bài viết sau đây, chúng ta sẽ cùng tìm hiểu về Microsoft Fabric Notebook - một giải pháp phân tích dữ liệu toàn diện tích hợp trí tuệ nhân tạo AI phát triển bởi Microsoft, hứa hẹn giúp cải thiện quy trình xử lý dữ liệu của doanh nghiệp.
Đây là một bài viết trong series Data Science at Scale with Microsoft Fabric mà Team EDP sẽ ra mắt trong thời gian tới. Series tập trung vào các bài toán phân tích dữ liệu chuyên sâu thực tế mà doanh nghiệp có thể triển khai dựa trên sức mạnh công nghệ Microsoft Fabric đem lại.
Giới thiệu về Microsoft Fabric Notebook
Nhắc tới Notebook, các bạn làm Data Analyst, Data Engineer hay Data Scientist chắn hẳn đã rất quen thuộc rồi. Chúng ta có thể cài đặt Jupyter Notebook trên máy tính cá nhân hoặc sử dụng trực tuyến với Google Colab để thực hiện các tác vụ xử lý và phân tích dữ liệu.
Điều đặc biệt của Microsoft Fabric Notebook là bạn không mất nhiều thời gian và công sức để xây dựng hạ tầng dữ liệu mà tập trung vào giải quyết các vấn đề của doanh nghiệp:
- Các bạn làm Data Engineer có thể sử dụng Notebook thực hiện tác vụ xử lý dữ liệu như Data Ingestion, Data Crawling, Data Preparation, Data Transformation,...
- Các bạn làm Data Scientist cũng có thể sử dụng Notebook để xây dựng các mô hình phân tích chuyển sâu bằng Machine Learning, Deep Learning, AI.
Với Microsoft Fabric Notebook, bạn có thể:
- Bắt đầu mà không tốn nhiều công sức cài đặt
- Dễ dàng khám phá và xử lý dữ liệu một cách trực quan
- Đảm bảo tính bảo mật khi sử dụng dữ liệu. Dữ liệu được lưu trữ trong hạ tầng dữ liệu của doanh nghiệp
- Phân tích dữ liệu thô (CSV, TXT, JSON, ..) hoặc xử lý các định dạng file như Parquet, Delta Lake tận dụng sức mạnh của Spark
- Còn rất nhiều điều có thể làm nữa mà chưa thể liệt kê hết được 😀
Bắt đầu ngay mà không cần phải cài đặt bất kỳ thư viện nào nhờ có sẵn Spark Cluster
Microsoft Fabric Notebook là một nền tảng lập trình trực tuyến, mang lại trải nghiệm thuận tiện và linh hoạt cho người dùng trong việc thực hiện dự án khoa học dữ liệu.
Với việc đã được kết nối đến một Spark Cluster có sẵn, người dùng không cần lo lắng về quá trình cài đặt các thư viện. Người dùng có thể bắt đầu ngay lập tức với môi trường đã được thiết lập trước và sẵn có các thư viện phổ biến.
Microsoft Fabric Notebook không chỉ hỗ trợ tương tác cao và chia sẻ dễ dàng, mà còn đa ngôn ngữ, giúp người dùng linh hoạt trong lựa chọn ngôn ngữ theo nhu cầu cụ thể của họ.
Ngoài ra, với sự chú trọng trong việc bảo mật dữ liệu - đảm bảo an toàn cho thông tin cá nhân và dự án, Microsoft Fabric Notebook trở thành một công cụ lý tưởng cho việc thực hiện các dự án khoa học dữ liệu mà không gặp khó khăn trong quá trình cài đặt.
Kết nối trực tiếp tới OneLake
Một điểm khác biệt nữa của Microsoft Fabric Notebook so với các nền tảng hoặc môi trường chạy các tác vụ Data Science khác là sự kết nối đến một Lakehouse có trong OneLake – nền tảng lưu trữ dữ liệu chính của Microsoft Fabric. Điều này cho phép chúng ta thao tác dễ dàng với các bảng và các tập dữ liệu đã sẵn có trong Lakehouse.
Chúng ta có thể chọn Lakehouse có sẵn hoặc tạo mới một Lakehouse để bắt đầu sử dụng dữ liệu.

Các tính năng nổi bật của Microsoft Fabric Notebook
Sử dụng nhiều ngôn ngữ lập trình khác nhau
Một notebook có nhiều ô (cells), và chúng ta có thể linh hoạt thay đổi ngôn ngữ sử dụng của mỗi ô.
Dưới đây là danh sách các ngôn ngữ mà Microsoft Fabric Notebook hỗ trợ, đi kèm đó là ngôn ngữ mà nó hỗ trợ:
| Code | Ngôn ngữ |
|---|---|
| Python | |
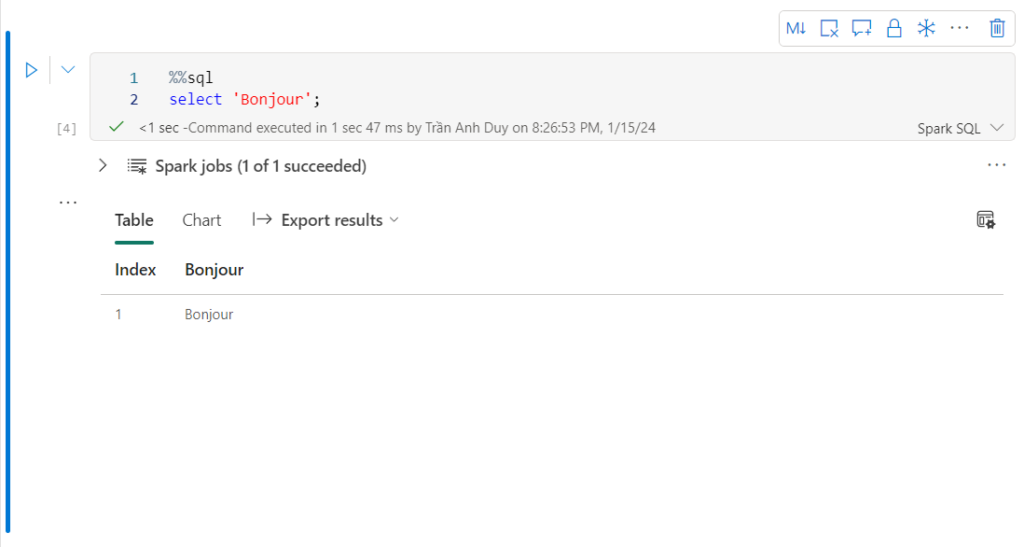
| %%sql | SQL |
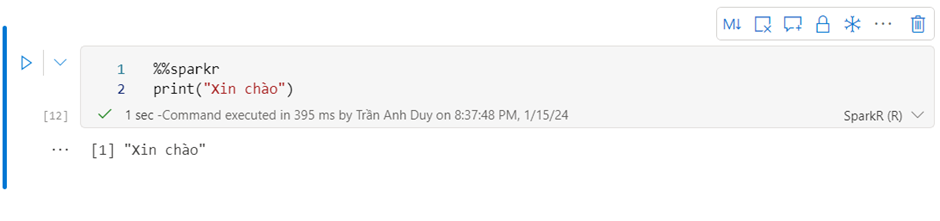
| %%sparkr | R |
| %%spark | Scala |
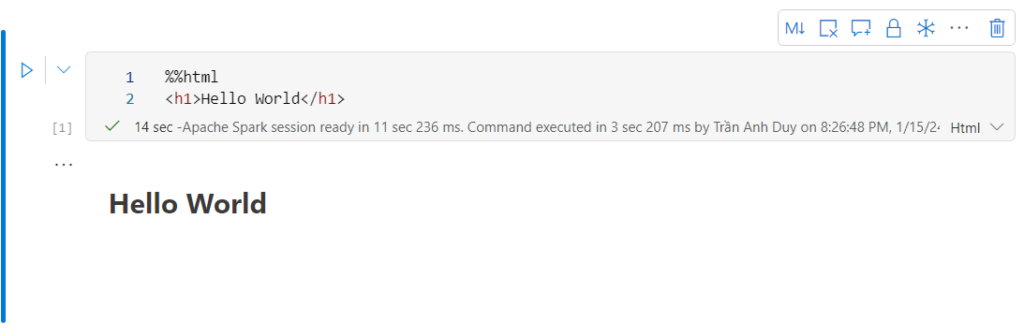
| %%html | HTML |
Dưới đây là 1 vài ví dụ khi chạy với các ngôn ngữ mà Microsoft Fabric Notebook hỗ trợ:

Ngoài ra, Notebook còn có thể giúp chúng ta viết Markdown – một ô dùng để ghi chú chức năng của đoạn code.
Kéo, thả để đưa dữ liệu vào Notebook
Tính năng kéo thả là một trong nhiều cách khác nhau để đưa dữ liệu từ một Lakehouse đã chọn vào trong Microsoft Fabric Notebook, chỉ bao gồm những thao tác đơn giản: chọn tập dữ liệu cần sử dụng và kéo chúng vào Notebook và chạy ô code đó.
Sau khi thực hiện, Notebook sẽ tạo ra 1 ô code chứa đoạn code để nhập dataset từ Lakehouse, và chúng ta đã có thể sử dụng dataset đó.

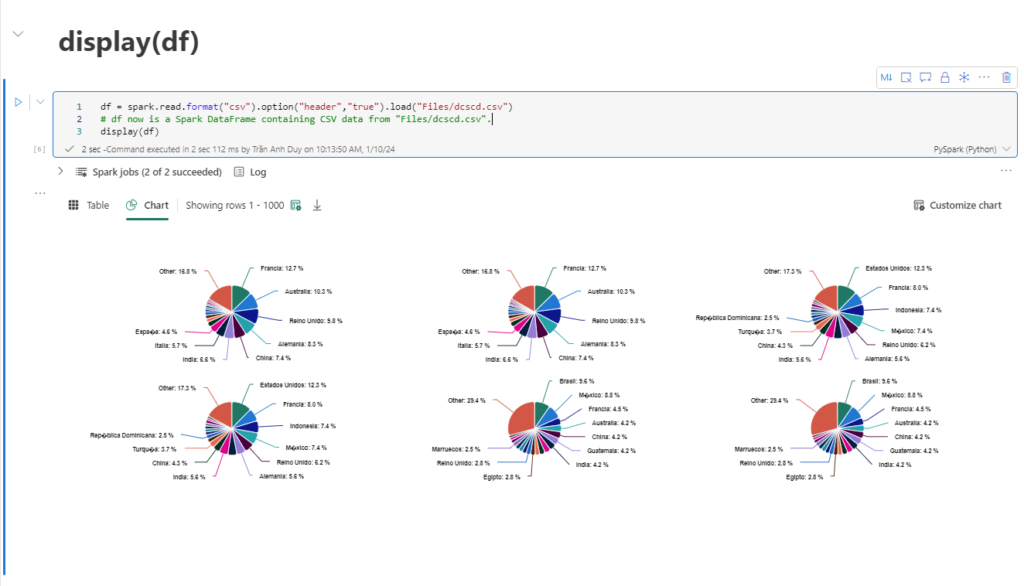
Hàm "display(df)"
Trong môi trường PySpark, Spark Scala và Spark SQL có trong Notebook, hàm display(df) không chỉ giúp chúng ta xem các giá trị trong tập dữ liệu theo dạng bảng mà còn giúp chúng ta xem các giá trị đó theo một cách sinh động, dễ nhìn hơn bằng các biểu đồ.
Lựa chọn Chart -> chọn các trường mà chúng ta muốn xem, Microsoft Fabric Notebook sẽ tạo ra các biểu đồ theo nhiều dạng khác nhau nhằm giúp chúng ta có thêm nhiều cách để xem dữ liệu hơn.
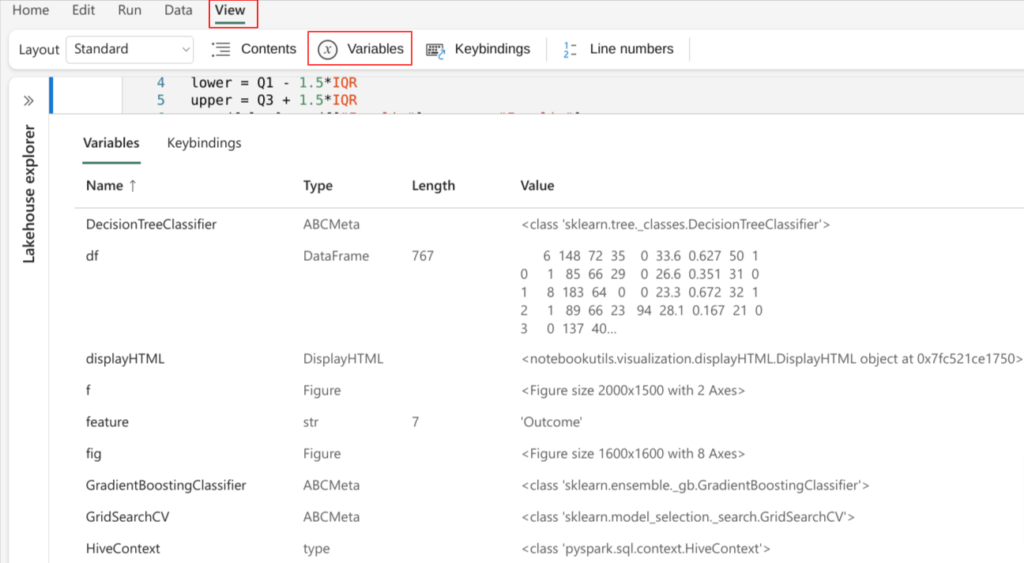
Xem các biến một cách dễ dàng
Microsoft Fabric Notebook có một chức năng cho phép chúng ta có thể dễ dàng xem danh sách các biến trong một session và các thuộc tính của chúng bao gồm tên, loại dữ liệu, độ dài, giá trị.
Một khi đã có biến được khai báo trong các ô code, chúng sẽ được tự động hiển thị trong mục Variables. Hơn nữa, bằng cách chọn bất kỳ cột nào, người dùng có thể sắp xếp các biến trong bảng một cách thuận tiện dựa trên các thuộc tính tương ứng của chúng.
Để xem các biến, người dùng chọn Variables trong tab View.
Lưu ý: Tính năng Variables chỉ hỗ trợ với ngôn ngữ lập trình Python. Nó chỉ có khả năng tương tác và làm việc với mã nguồn dựa trên ngôn ngữ lập trình Python, và không mở rộng hỗ trợ của mình cho các ngôn ngữ lập trình khác mà Fabric hỗ trợ.
Data Wrangler
Những người làm vị trí Data Scientist thường phải làm việc với dữ liệu, đặc biệt là khâu chuẩn bị và làm sạch dữ liệu. Điều này rất cần thiết để Data Scientist hiểu được dữ liệu, và là một phần của quá trình thực hiện để chuẩn bị dữ liệu và đưa dữ liệu vào một mô hình để phân tích chuyên sâu.
Hơn nữa, dữ liệu đóng vai trò tối quan trọng, ảnh hưởng trực tiếp đến kết quả phân tích và dự đoán của một mô hình Machine Learning. Vì vậy, các bước chuẩn bị dữ liệu trước khi đưa vào phân tích là rất cần thiết.
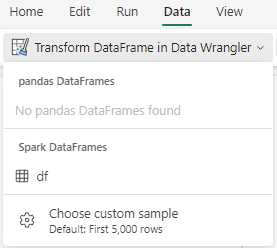
Ở thanh tùy chọn trong mỗi file Notebook, ở phần Data, người dùng có thể lựa chọn Transfer DataFrame in Data Wrangler để khởi động trình sắp xếp dữ liệu.
Bằng cách chọn DataFrame mong muốn từ menu Spark DataFrame, người dùng có thể mở nó trong Data Wrangler, từ đó có thể thuận lợi thao tác với dữ liệu và khai phá dữ liệu hiệu quả hơn.
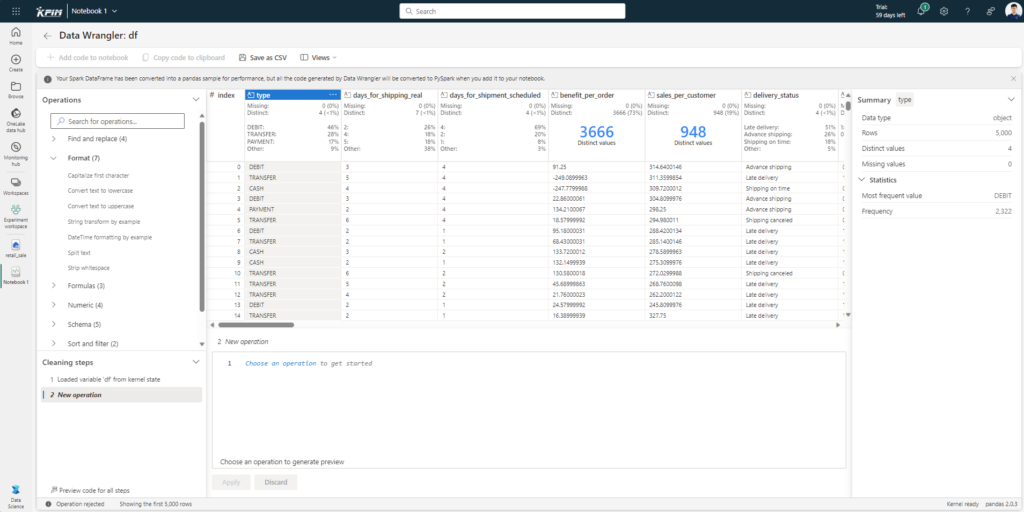
Các thành phần chính có trong Data Wrangler:
- Mục Summary tạo ra một cái nhìn tổng quan về DataFrame, gồm chiều, giá trị trống... Khi chọn một cột, mục này sẽ đưa ra thống kê cụ thể cho cột đó.
- Mục Column statistics bao gồm một bảng xuất hiện ở trên mỗi cột, cho phép chúng ta có cái nhìn tổng quan nhất về dữ liệu có trong cột đó.
- Mục Operations chứa một danh sách có thể tìm kiếm các bước làm sạch dữ liệu. Người dùng có thể dễ dàng truy cập bảng này để khám phá và sử dụng các thao tác khác nhau để làm sạch và biến đổi dữ liệu.
- Mục Cleaning steps hiển thị các bước làm sạch dữ liệu theo thứ tự mong muốn của người dùng.
- Mục Code preview sẽ cho chúng ta xem các đoạn code dùng để thực hiện từng bước trong mục Cleaning steps.
- Cuối cùng, chúng ta có thể lưu dữ liệu sau khi đã được xử lý ở Data Wrangler bằng cách ấn nút Save as CSV, hoặc đưa đoạn code xử lý dữ liệu bằng cách chọn Add code to notebook.
Kết luận
Như vậy, chúng ta đã có cái nhìn tổng quan nhất về Microsoft Fabric Notebook, với các điểm nổi bật so với các nền tảng Notebook khác, đặc biệt là khả năng liên kết đến một Lakehouse có sẵn và rất nhiều tính năng thú vị.
Hy vọng là bài viết này đã đưa ra cho các bạn cái nhìn khái quát về một trong những tính năng quan trọng nhất có trong Microsoft Fabric.





