


Phương pháp CDC với Fabric với MySQL và Postgres
TỔNG QUAN PHƯƠNG PHÁP
Sao Real-time lại cần thiết?
Hình 1.1: Ví dụ minh hoạ về Streaming
Real-time (tính tức thời) đề cập đến khả năng xử lý và phản hồi các sự kiện dữ liệu ngay khi chúng xảy ra. Trong bối cảnh của các hệ thống quản lý cơ sở dữ liệu quan hệ (Relational Database Management Systems – RDBMS) như MySQL và PostgreSQL, việc áp dụng Change Data Capture (CDC) có thể giúp các tổ chức nhận biết và hành động dựa trên dữ liệu mới nhất mà không cần chờ đợi các quá trình xử lý dữ liệu hàng loạt truyền thống. Điều này cải thiện khả năng ra quyết định và tăng cường hiệu quả hoạt động kinh doanh.
Change Data Capture (CDC) là gì?
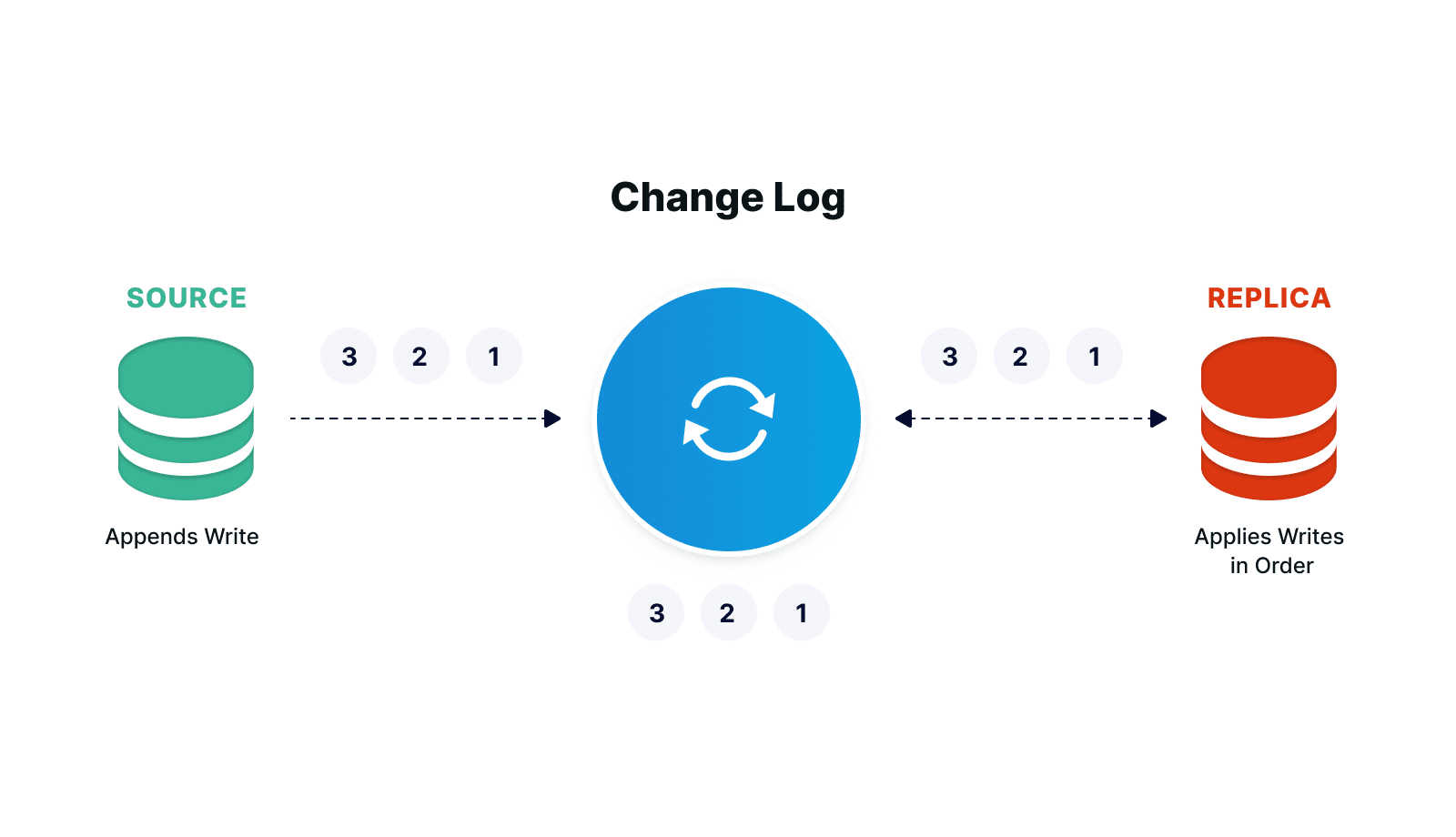
Hình 1.2: Ví dụ minh hoạ về CDC
Change Data Capture (CDC) là một kỹ thuật ghi nhận và theo dõi các thay đổi dữ liệu trong cơ sở dữ liệu thời gian thực. Cụ thể, CDC phát hiện và ghi lại các thao tác như thêm mới, cập nhật hoặc xóa dữ liệu trong cơ sở dữ liệu và sau đó cung cấp những thay đổi này cho các hệ thống khác hoặc lưu trữ chúng để xử lý sau. Phương pháp này đặc biệt hữu ích trong các hệ thống cần cập nhật dữ liệu liên tục và kịp thời, chẳng hạn như phân tích dữ liệu, báo cáo kinh doanh và tích hợp dữ liệu từ nhiều nguồn khác nhau.
Giới thiệu qua về MySQL và PostgreSQL
![]()
Hình 1.3: MySQL logo
MySQL: MySQL là một hệ quản trị cơ sở dữ liệu mã nguồn mở phổ biến, được sử dụng rộng rãi cho các ứng dụng web và doanh nghiệp. Với hiệu suất cao và khả năng mở rộng,
MySQL là lựa chọn ưa thích cho nhiều ứng dụng thời gian thực. CDC trong MySQL thường được triển khai bằng cách sử dụng tính năng binlog (binary logging), ghi lại các thay đổi dữ liệu để dễ dàng truy xuất và xử lý sau.
![]()
Hình 1.4: Postgres logo
PostgreSQL: PostgreSQL là một hệ quản trị cơ sở dữ liệu quan hệ mạnh mẽ và linh hoạt, nổi tiếng với các tính năng tiên tiến và tuân thủ các tiêu chuẩn SQL. PostgreSQL hỗ trợ CDC thông qua tính năng logical replication, cho phép ghi nhận và sao chép các thay đổi dữ liệu từ một cơ sở dữ liệu này sang một cơ sở dữ liệu khác hoặc hệ thống xử lý khác.
CHI TIẾT GIẢI PHÁP
Giới Thiệu về Docker
![]()
Hình 2.1: Docker logo
Docker là một nền tảng mã nguồn mở cho phép các nhà phát triển xây dựng, triển khai và chạy các ứng dụng trong các container. Container hóa cung cấp một cách để đóng gói một ứng dụng cùng với tất cả các thành phần cần thiết như thư viện, mã nguồn, và cấu hình, giúp đảm bảo rằng ứng dụng sẽ chạy đồng nhất trên mọi môi trường.
Giới thiệu về Debezium và Debezium UI
- Debezium: Debezium là một nền tảng mã nguồn mở cung cấp các công cụ để theo dõi các thay đổi dữ liệu trong cơ sở dữ liệu và truyền chúng đến các hệ thống khác như Kafka. Debezium hỗ trợ nhiều hệ quản trị cơ sở dữ liệu bao gồm MySQL, PostgreSQL, MongoDB, và nhiều hơn nữa. Nó cho phép các ứng dụng phản hồi kịp thời với các thay đổi dữ liệu, từ đó hỗ trợ các yêu cầu xử lý dữ liệu thời gian thực.
- Debezium UI: Debezium UI là giao diện người dùng cho Debezium, giúp dễ dàng quản lý và giám sát các kết nối và luồng dữ liệu CDC. Nó cung cấp các công cụ để cấu hình, kiểm tra, và giám sát hoạt động của Debezium connectors, giúp đơn giản hóa quá trình triển khai và quản lý CDC.
Giải pháp CDC với MySQL
- Kích hoạt binlog trong MySQL:
- Để bật CDC trong MySQL, bạn cần bật tính năng binlog bằng cách cấu hình tệp my.cnf hoặc my.ini.
- Kích Hoạt Logical Replication trong PostgreSQL:
- Để bật Change Data Capture (CDC) trong PostgreSQL, bạn cần kích hoạt tính năng logical replication. Logical replication cho phép theo dõi và ghi nhận các thay đổi dữ liệu trong cơ sở dữ liệu, giúp các hệ thống khác có thể tiêu thụ và xử lý dữ liệu thay đổi này.
- Sử dụng công cụ Debezium:
- Debezium là một nền tảng mã nguồn mở cho phép CDC trên nhiều hệ quản trị cơ sở dữ liệu khác nhau.
- Để sử dụng Debezium với MySQL, bạn cần cấu hình một connector để ghi nhận các thay đổi từ binlog và đẩy chúng vào Kafka.
Giới thiệu về Kafka và Control Center
- Kafka: Apache Kafka là một nền tảng xử lý luồng phân tán, được thiết kế để xử lý các luồng dữ liệu lớn theo thời gian thực. Kafka hoạt động như một hàng đợi tin nhắn phân tán, lưu trữ các bản ghi sự kiện và cho phép các hệ thống tiêu thụ và xử lý chúng theo cách mạnh mẽ và linh hoạt. Kafka được sử dụng rộng rãi trong các hệ thống xử lý dữ liệu thời gian thực, phân tích dữ liệu, và các ứng dụng IoT.
- Control Center: Kafka Control Center là một công cụ quản lý và giám sát cho các cụm Kafka. Nó cung cấp giao diện người dùng để giám sát hiệu suất, cấu hình và quản lý các topic, producer, và consumer trong Kafka. Control Center giúp các nhà phát triển và quản trị viên dễ dàng quản lý các luồng dữ liệu trong Kafka, từ đó tối ưu hóa hiệu suất và độ tin cậy của hệ thống.
Set-up và thực hiện:
Để cài đặt Docker Desktop, bạn có thể làm theo các bước ngắn gọn sau:
- Tải Docker Desktop:
- Truy cập trang tải Docker (Install Docker Desktop on Windows | Docker Docs) và tải phiên bản phù hợp với hệ điều hành của bạn (Windows, macOS, hoặc Linux).
- Cài đặt Docker Desktop:
- Windows:
- Chạy file cài đặt đã tải về (.exe).
- Làm theo hướng dẫn trên màn hình, bao gồm việc chọn các tùy chọn mặc định và chấp nhận các điều khoản dịch vụ.
- Khởi động lại máy tính nếu được yêu cầu.
- macOS:
- Mở file cài đặt đã tải về (.dmg).
- Kéo biểu tượng Docker vào thư mục Applications.
- Khởi chạy Docker Desktop từ Applications.
- Linux:
- Làm theo hướng dẫn cụ thể cho bản phân phối Linux của bạn trên Docker Docs.
- Windows:
- Khởi động Docker Desktop:
- Mở Docker Desktop từ menu Start (Windows), Applications (macOS), hoặc terminal (Linux).
- Kiểm tra Docker:
Hình 3.1: Kiểm tra phiên bản Docker
- Mở terminal hoặc command prompt và chạy lệnh docker –version để kiểm tra xem Docker đã được cài đặt thành công chưa.
- Đăng nhập Docker Hub:
- Nếu bạn có tài khoản Docker Hub, đăng nhập vào Docker Desktop bằng thông tin đăng nhập của bạn để quản lý và tải các image từ Docker Hub.
Cấu hình file docker-compose.yml:
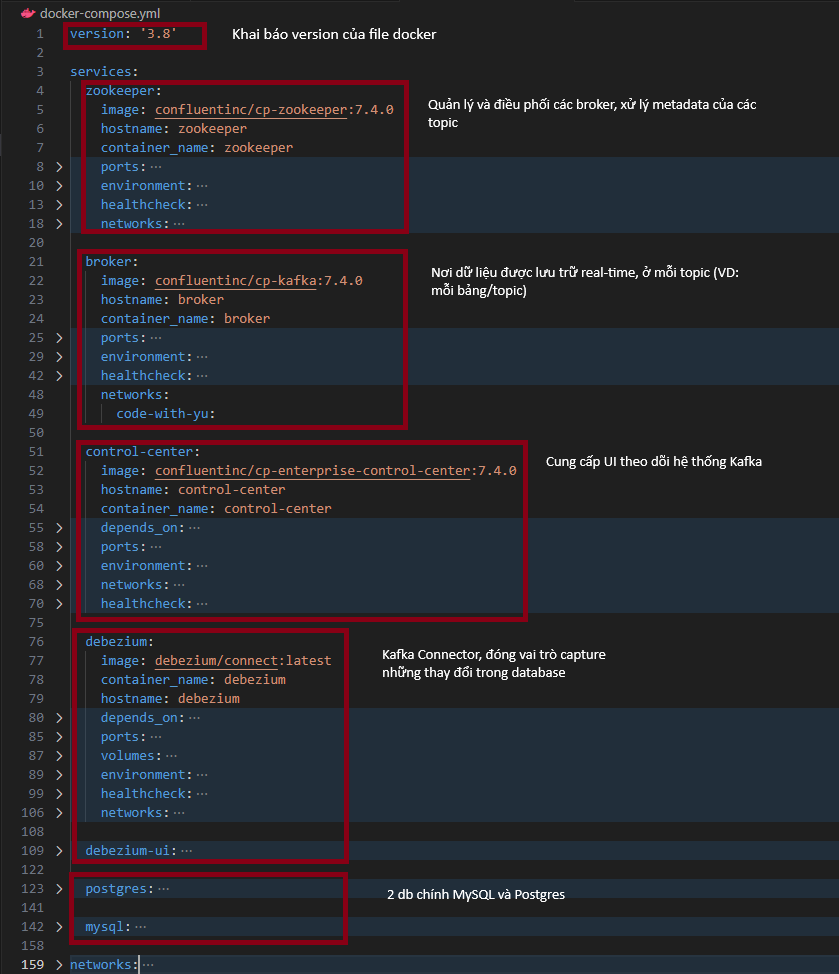
Hình 3.2: Tổng quan đơn giản về hệ thống
- Link tham khảo (Realtime Change Data Capture Streaming | End to End Data Engineering Project (youtube.com))
1. Chạy với lệnh command trong Docker
PostgreSQL
Để bật CDC trong PostgreSQL, bạn cần kích hoạt logical replication. Bạn có thể thực hiện điều này bằng cách thêm lệnh command trong Docker Compose file:
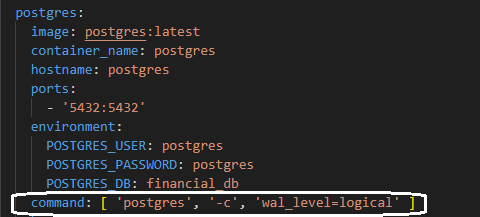
Hình 3.3: Set-up CDC cho database Postgres
2. Set up 1 file config và mount với local file
MySQL: Tạo file cấu hình my.cnf với nội dung sau
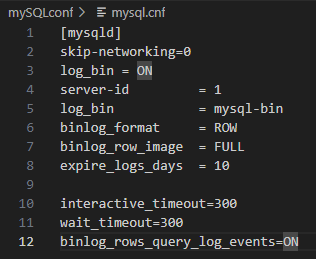
Hình 3.4.1: Set-up CDC cho database MySQL
Bạn có thể tạo các file cấu hình riêng biệt và mount chúng vào Docker containers.
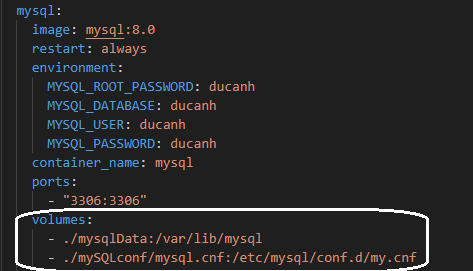
Hình 3.4.2: Set-up CDC cho database MySQL
-
- Check file đã thực sự mount bằng cách kiểm tra trong Docker Container:
Vào Docker container MySQL -> Bind mount
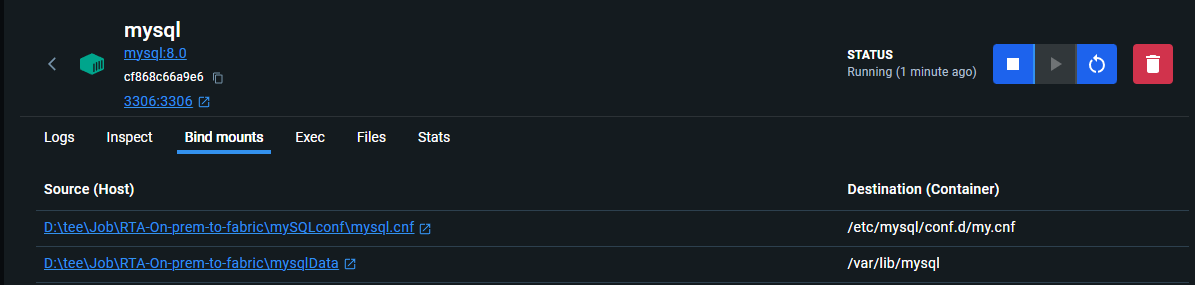
Hình 3.5: Check mount trong Docker
Build-up các Container:
- Chạy lệnh docker-compose up -d để khởi động các container.
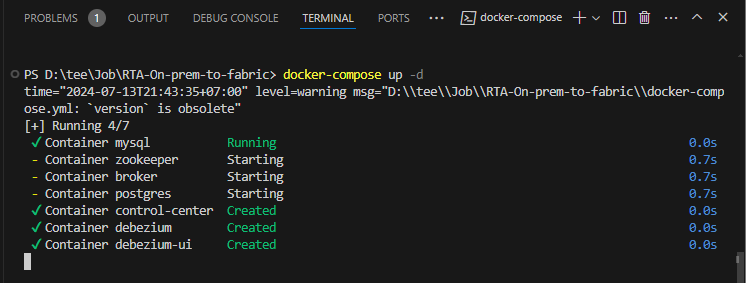
Hình 3.6: Building Docker containers
- Note: Nếu có một vài container failed khi build-up, bạn có thể vào Docker Desktop để start thủ công các container đó. Bạn cũng có thể kiểm tra log để xác định nguyên nhân lỗi và khắc phục.

Hình 3.7: Building Docker containers manually
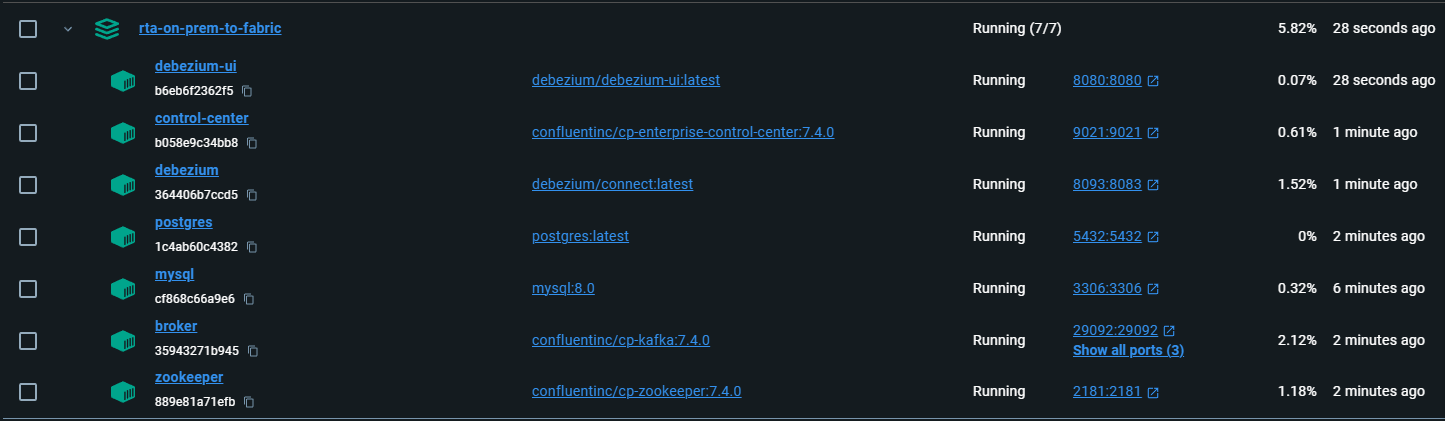
Hình 3.8: Successfully Start
Sau khi các Container được set up thành công
Sau khi các container được set up thành công, bạn cần tiếp tục việc thiết lập các database chính. Điều này có thể bao gồm việc tạo các bảng, cấu hình Debezium connectors, và chạy các script Python để tạo và xử lý giao dịch giả.
Cài Đặt Database với DBeaver
DBeaver là một công cụ quản lý cơ sở dữ liệu phổ biến hỗ trợ nhiều loại cơ sở dữ liệu, bao gồm MySQL. Dưới đây là cách bạn có thể cài đặt một cơ sở dữ liệu và nhập dữ liệu mẫu vào trong DBeaver:
Hướng Dẫn Chi Tiết
Tải và Cài Đặt DBeaver: Download | DBeaver Community

Hình 4.1: DBeaver
- Nếu bạn chưa có DBeaver, hãy tải và cài đặt từ trang web chính thức.
Tạo Kết Nối Mới:
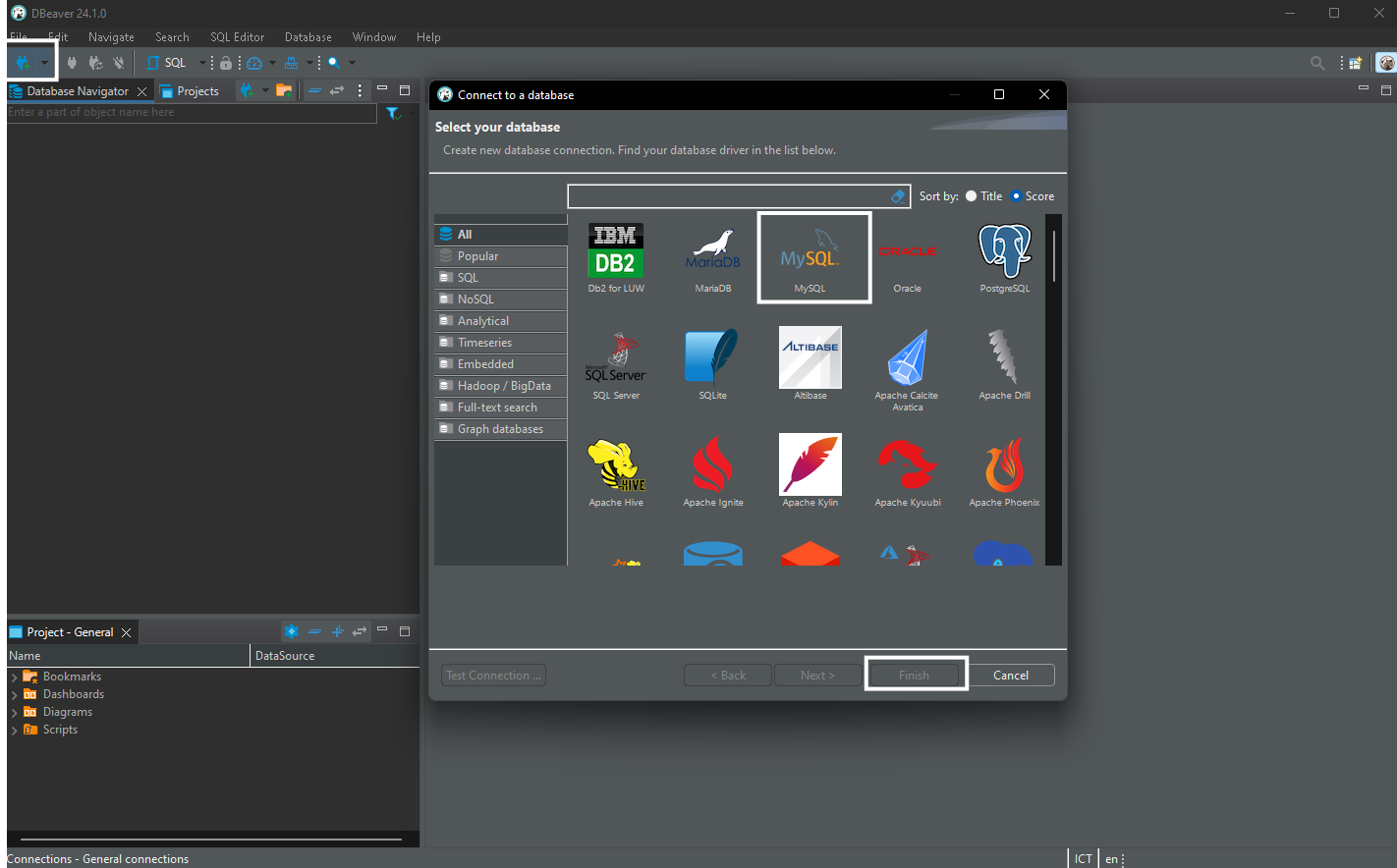
Hình 4.2: Create Connection
- Mở DBeaver.
- Nhấp vào menu Database và chọn New Database Connection.
- Chọn MySQL:
- Trong hộp thoại Connect to a database, tìm và chọn MySQL.
- Nhấp vào Next.
- Điền Thông Tin Kết Nối:
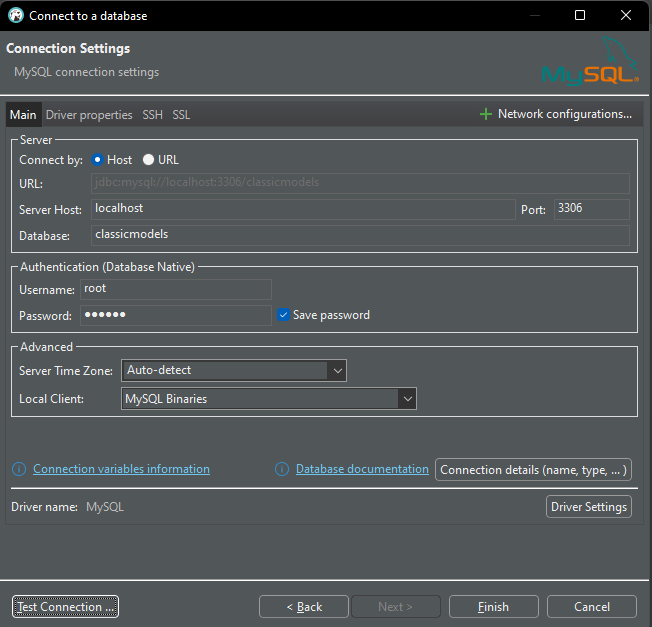
Hình 4.3: Điền Config
- Điền thông tin kết nối:
-
-
- Host: localhost (hoặc địa chỉ IP của server MySQL của bạn)
- Port: 3306 (port mặc định của MySQL)
- Database: retail_db (hoặc bất kỳ tên cơ sở dữ liệu nào bạn muốn)
- Username: Tên người dùng MySQL của bạn (ví dụ: root)
- Password: Mật khẩu MySQL của bạn
- Nhấp vào Test Connection để đảm bảo kết nối thành công.
- Nhấp vào Finish để lưu kết nối.
-
Mở Một Script SQL Mới:
- Trong DBeaver, nhấp chuột phải vào kết nối mới tạo
Nhập Dữ Liệu Mẫu SQL:
- Bạn cần tải xuống script SQL cơ sở dữ liệu mẫu. Cơ sở dữ liệu mẫu MySQL có thể được tìm thấy ở đây. (MySQL Sample Database (mysqltutorial.org)
- Sau khi tải xuống file mysqlsampledatabase.sql, mở nó trong SQL Editor.

Hình 4.4: Database schema
Kiểm tra các bảng trong MySQL container
Truy cập vào MySQL container:
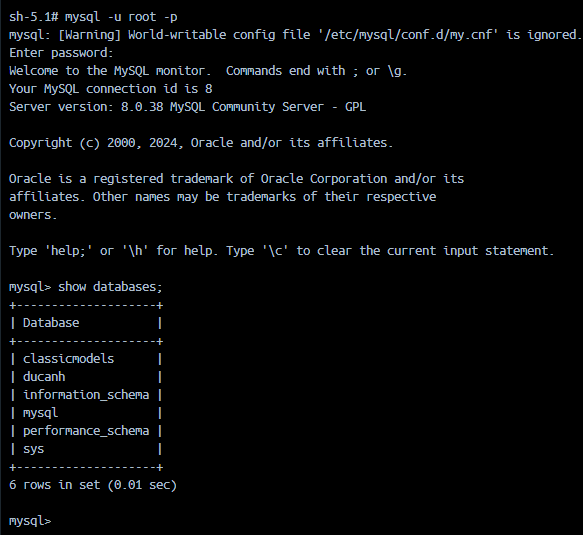
Hình 4.5: Check database
Hiển thị các cơ sở dữ liệu:
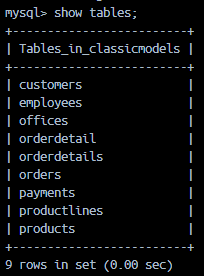
Hình 4.6: Database tables
Chọn cơ sở dữ liệu:
- USE <database_name>;
- SHOW TABLES;
Thiết lập kết nối Debezium qua giao diện người dùng (UI)
- Mở trình duyệt và truy cập http://localhost:8080.
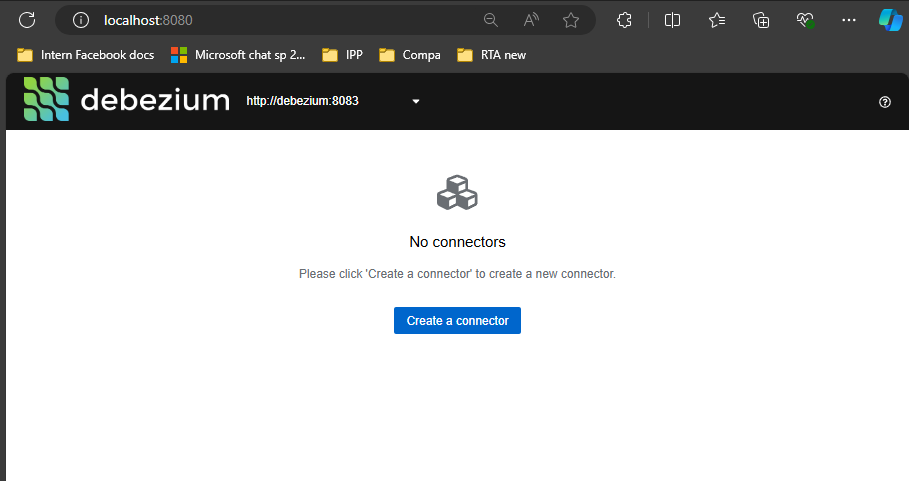
Hình 5.1: Create connection to DB
Tạo kết nối:
- Chọn MySQL làm nguồn dữ liệu.
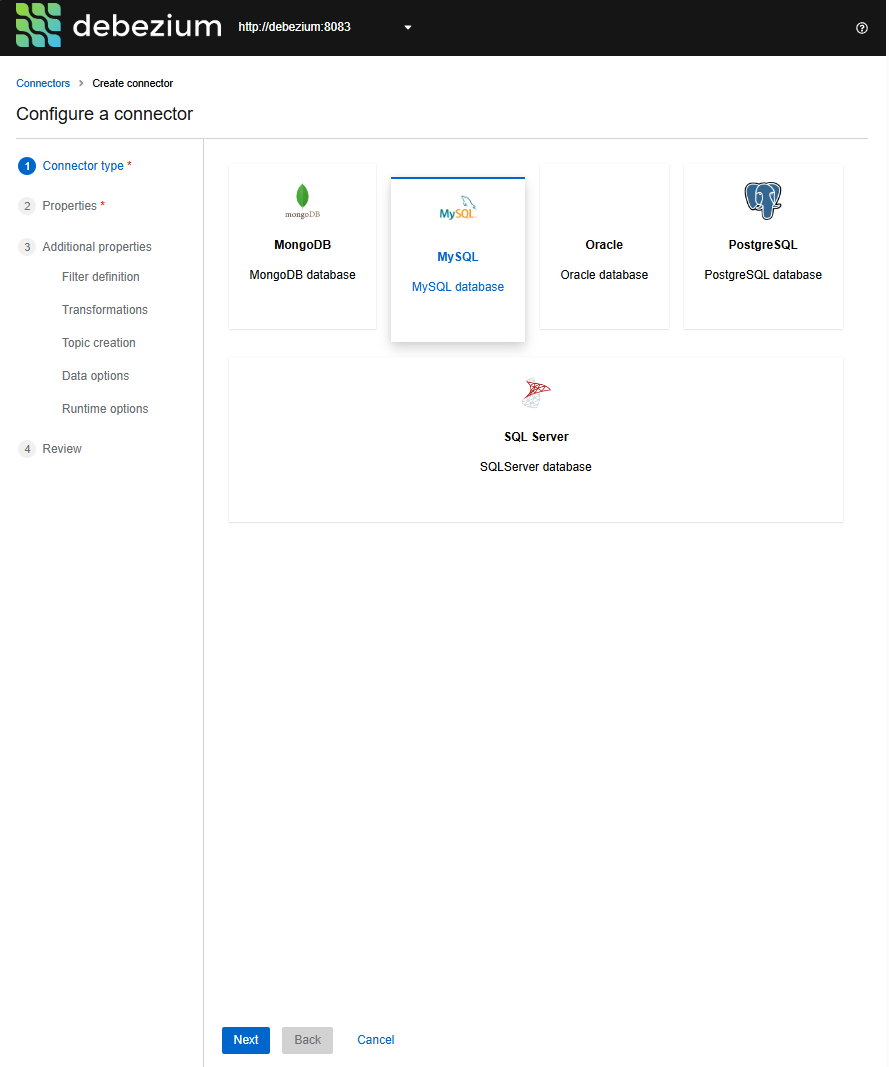 Hình 5.2: Chọn MySQL
Hình 5.2: Chọn MySQL
Điền thông tin cấu hình:
- Điền các thông tin cần thiết như Topic Prefix, địa chỉ của Kafka broker server, và các thông tin cần thiết khác.
- Thực hiện kiểm tra validation để đảm bảo rằng các thông tin đã điền đúng.
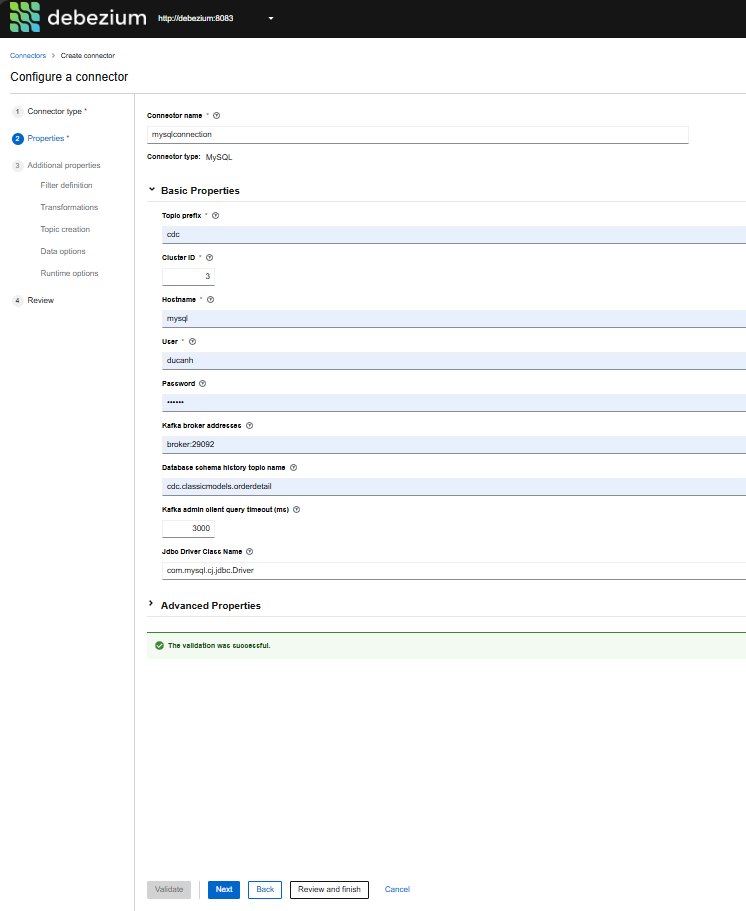
Hình 5.3: Điền thông tin DB và test connect
Docker Compose: Kafka auto.create.topics.enable
Trong file docker-compose.yml, bạn có thể cấu hình Kafka để tự động tạo các topic khi cần. Để kích hoạt tính năng này, bạn cần thêm dòng sau vào cấu hình Kafka:
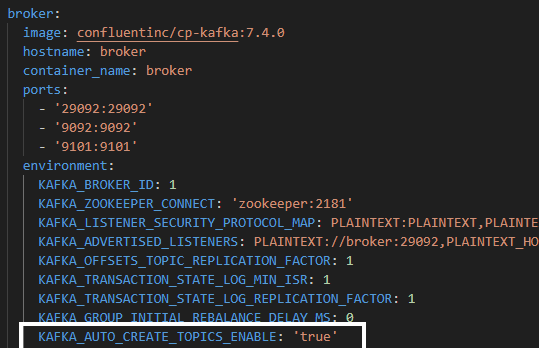
Hình 6.1: Config cho Kafka
Giải thích việc tự động tạo topic
Khi auto.create.topics.enable được bật, Kafka sẽ tự động tạo các topic mới khi chúng được tham chiếu lần đầu tiên. Điều này có nghĩa là bạn không cần phải tạo các topic thủ công cho từng bảng trong MySQL. Khi Debezium phát hiện các thay đổi trong MySQL, nó sẽ tự động tạo các topic tương ứng trong Kafka.
Các topic dựa trên từng bảng trong MySQL
Các topic sẽ được tạo tự động dựa trên từng bảng trong MySQL. Mỗi bảng trong MySQL sẽ có một topic tương ứng trong Kafka. Ví dụ:
- Bảng orderdetails trong MySQL sẽ có một topic tương ứng trong Kafka, thường có tên như cdc.clasicmodels.orderdetails.
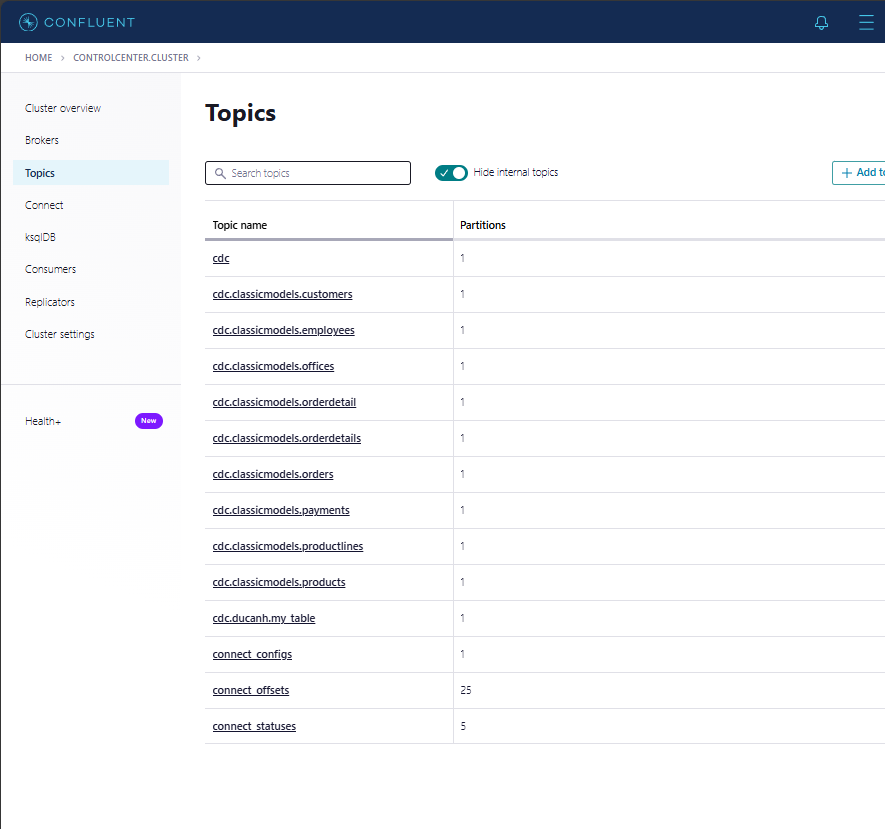
Hình 6.2: List các topic trên localhost:9021
Message ở dạng JSON
Các message trong Kafka sẽ được gửi ở định dạng JSON. Một ví dụ của một message JSON có thể trông như sau:
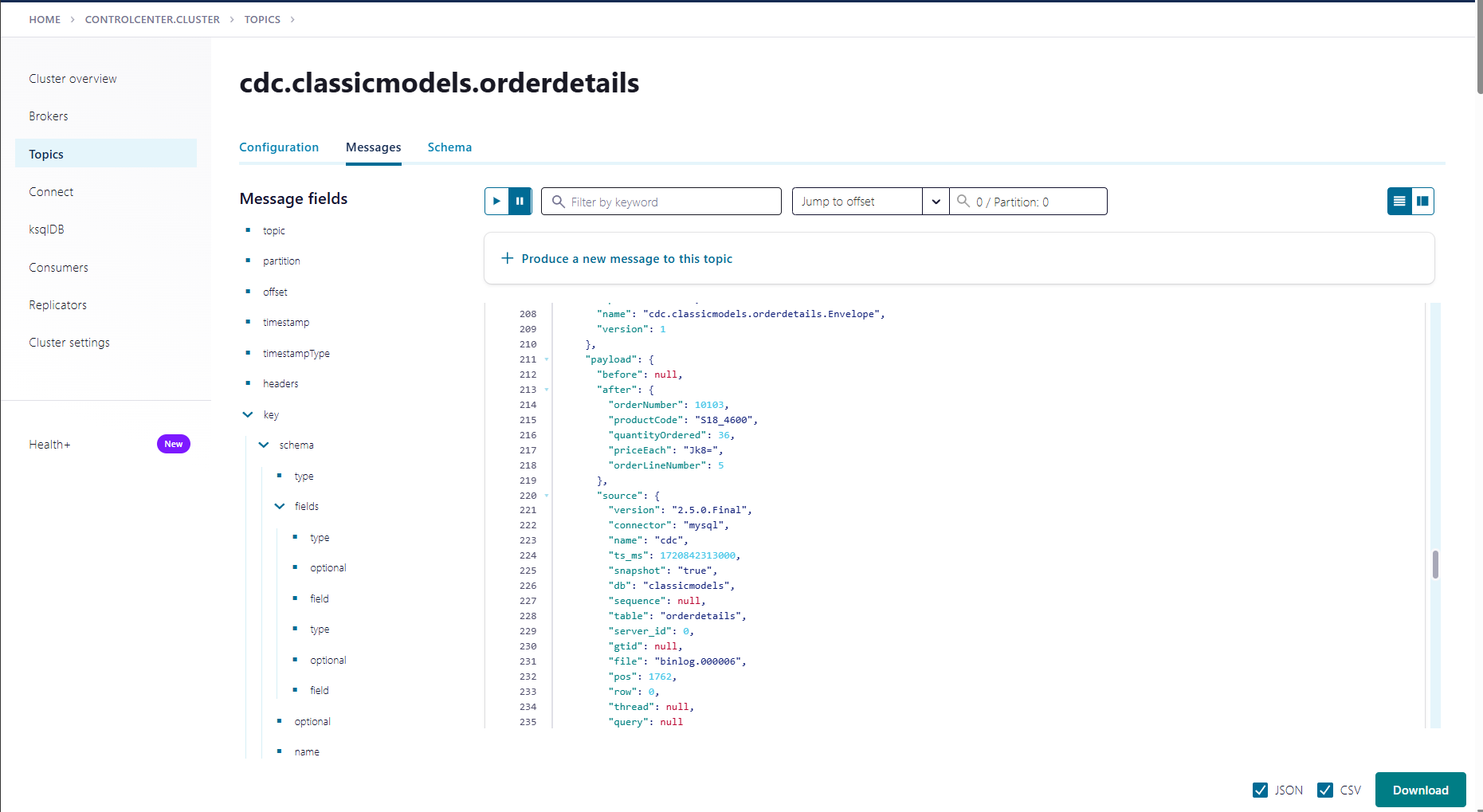
Hình 6.3: JSON data khi được CDC từ database
Set up Code để đọc từ Kafka và đẩy lên Fabric:
Cấu hình kết nối MySQL
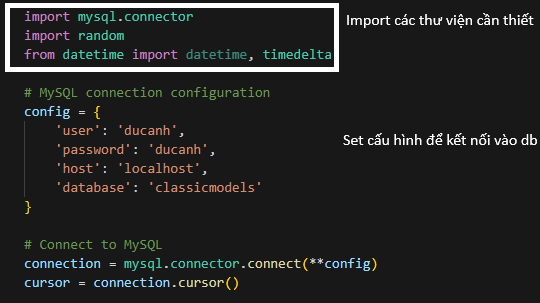
Hình 7.1: Config Local database
- mysql.connector: Thư viện này cung cấp các phương thức để kết nối và tương tác với MySQL.
- config: Cấu hình kết nối MySQL bao gồm tên người dùng, mật khẩu, host và tên cơ sở dữ liệu.
- connection: Tạo kết nối tới MySQL với các thông số đã cấu hình.
- cursor: Đối tượng này được sử dụng để thực hiện các truy vấn SQL.
Hàm tạo ngày ngẫu nhiên

Hình 7.2: Hàm fake datetime
- random_date(start, end): Hàm này tạo ra một ngày ngẫu nhiên giữa khoảng thời gian start và end.
- timedelta(days=random.randint(0, int((end – start).days))): Tạo một khoảng thời gian ngẫu nhiên từ start đến end.
Chèn dữ liệu giả vào bảng orderdetail
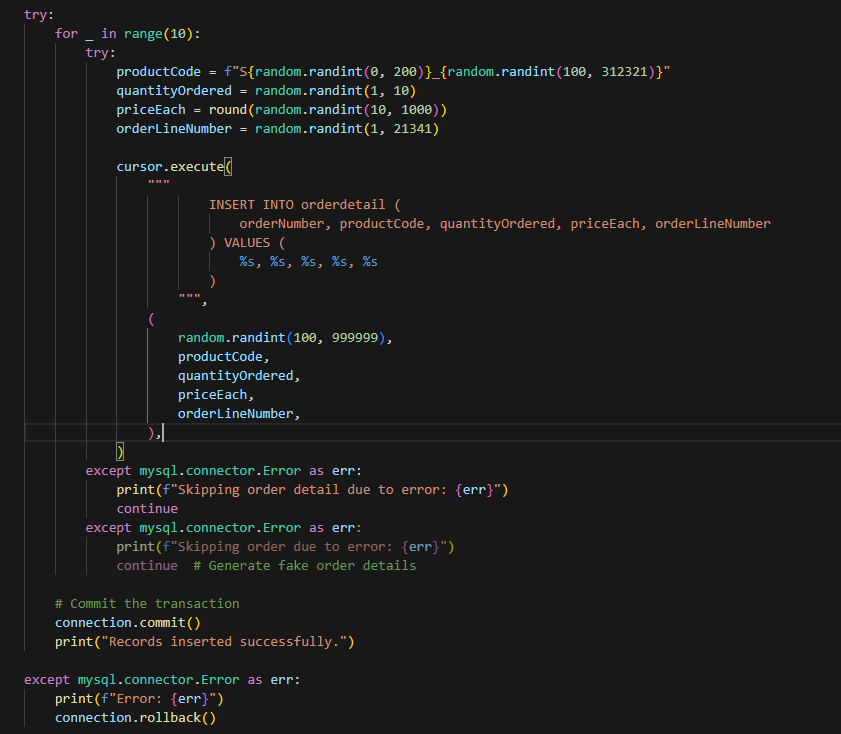
Hình 7.3: Generate fake data
- for _ in range(10): Lặp 10 lần để chèn 10 bản ghi.
- productCode, quantityOrdered, priceEach, orderLineNumber: Các giá trị ngẫu nhiên được tạo ra cho từng trường trong bảng orderdetail.
- cursor.execute(…): Thực hiện truy vấn chèn dữ liệu vào bảng orderdetail.
- except mysql.connector.Error as err: Bắt các lỗi xảy ra trong quá trình chèn và tiếp tục với bản ghi tiếp theo.
Cấu hình Kafka On-prem và Kafka Cloud Custom App:
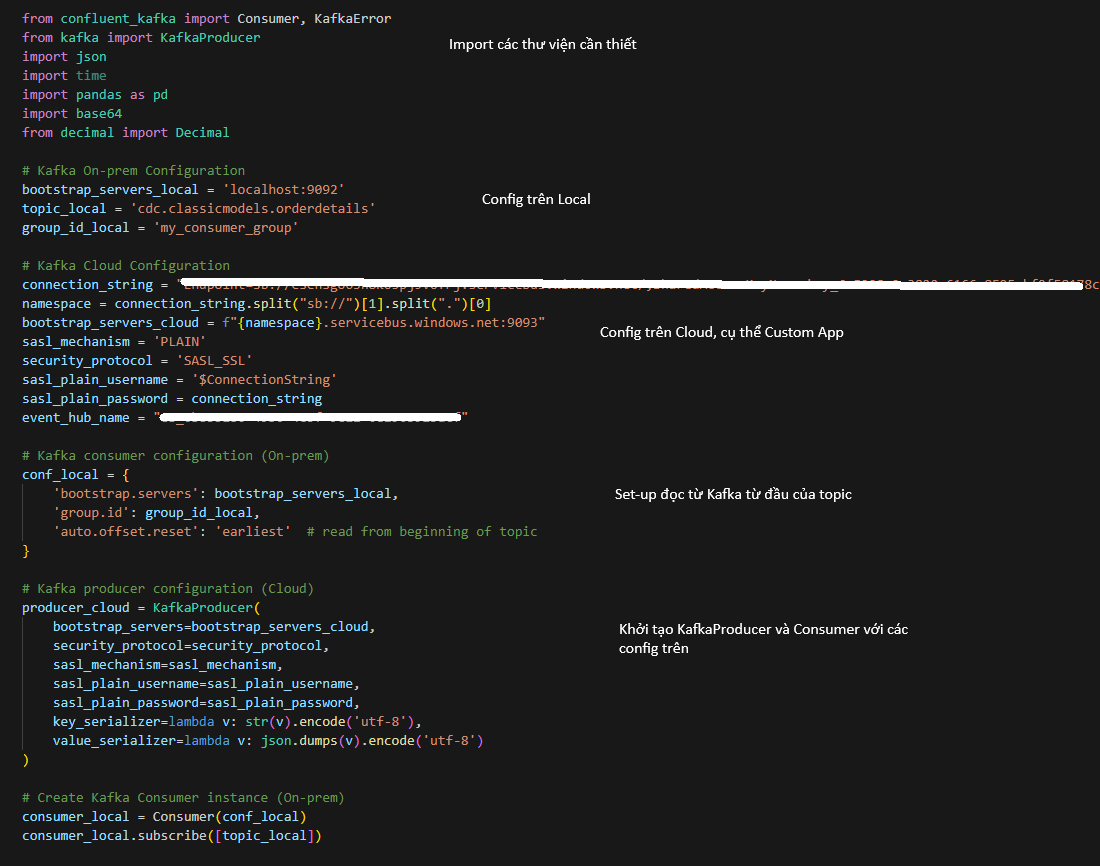
Hình 7.4: Push data to Cloud
Vòng lặp chính để xử lý tin nhắn từ Kafka
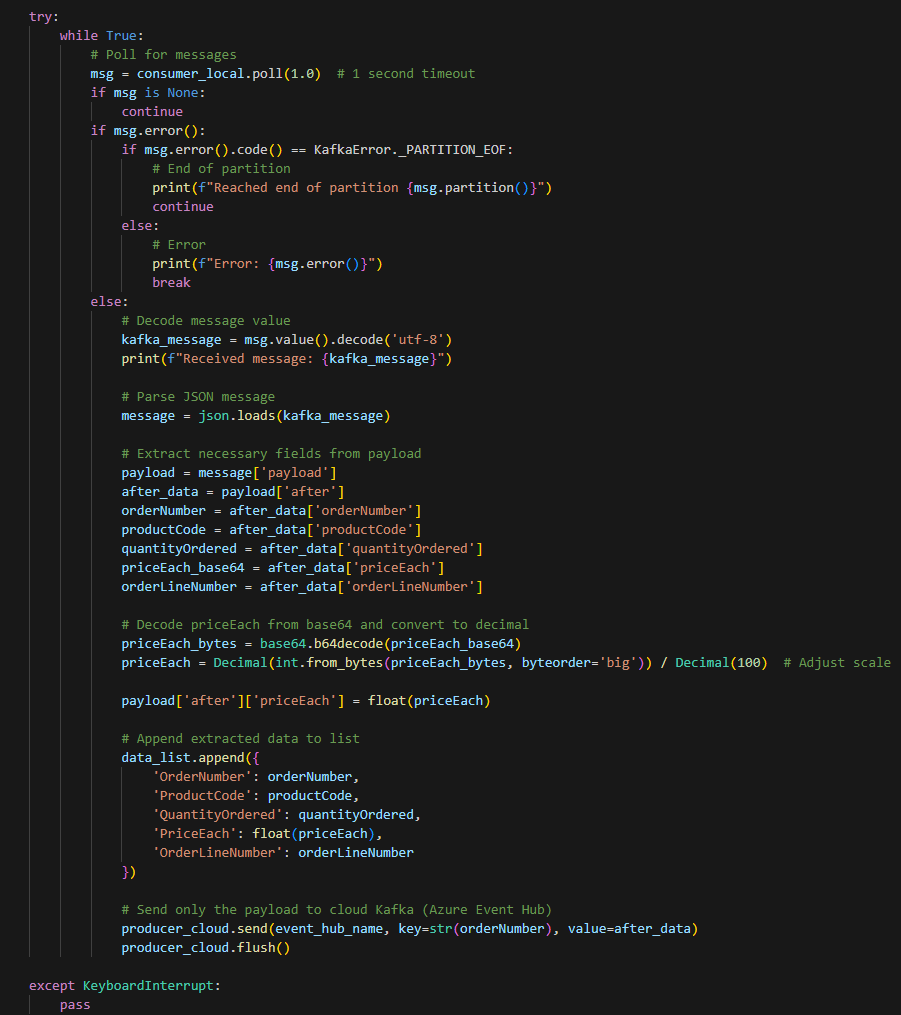
Hình 7.5: Transform data
- Vòng lặp while True để liên tục nhận tin nhắn từ Kafka topic.
- msg = consumer_local.poll(1.0): Nhận tin nhắn với timeout 1 giây.
- msg.error(): Kiểm tra lỗi và xử lý.
- msg.value().decode(‘utf-8’): Giải mã giá trị tin nhắn.
- json.loads(kafka_message): Phân tích cú pháp JSON từ tin nhắn.
- Trích xuất các trường cần thiết từ payload và giải mã priceEach từ base64.
- Chuyển đổi priceEach sang kiểu Decimal và điều chỉnh thang đo.
- Thêm dữ liệu trích xuất vào danh sách data_list.
- Gửi payload tới Kafka trên đám mây (Azure Event Hub).
Kiểm tra dữ liệu trên Fabric và cũng như Eventstream:
Check dữ liệu ở trên Fabric, tại đây bạn có thể xây dựng dashboard và transform data dựa trên Eventstream:
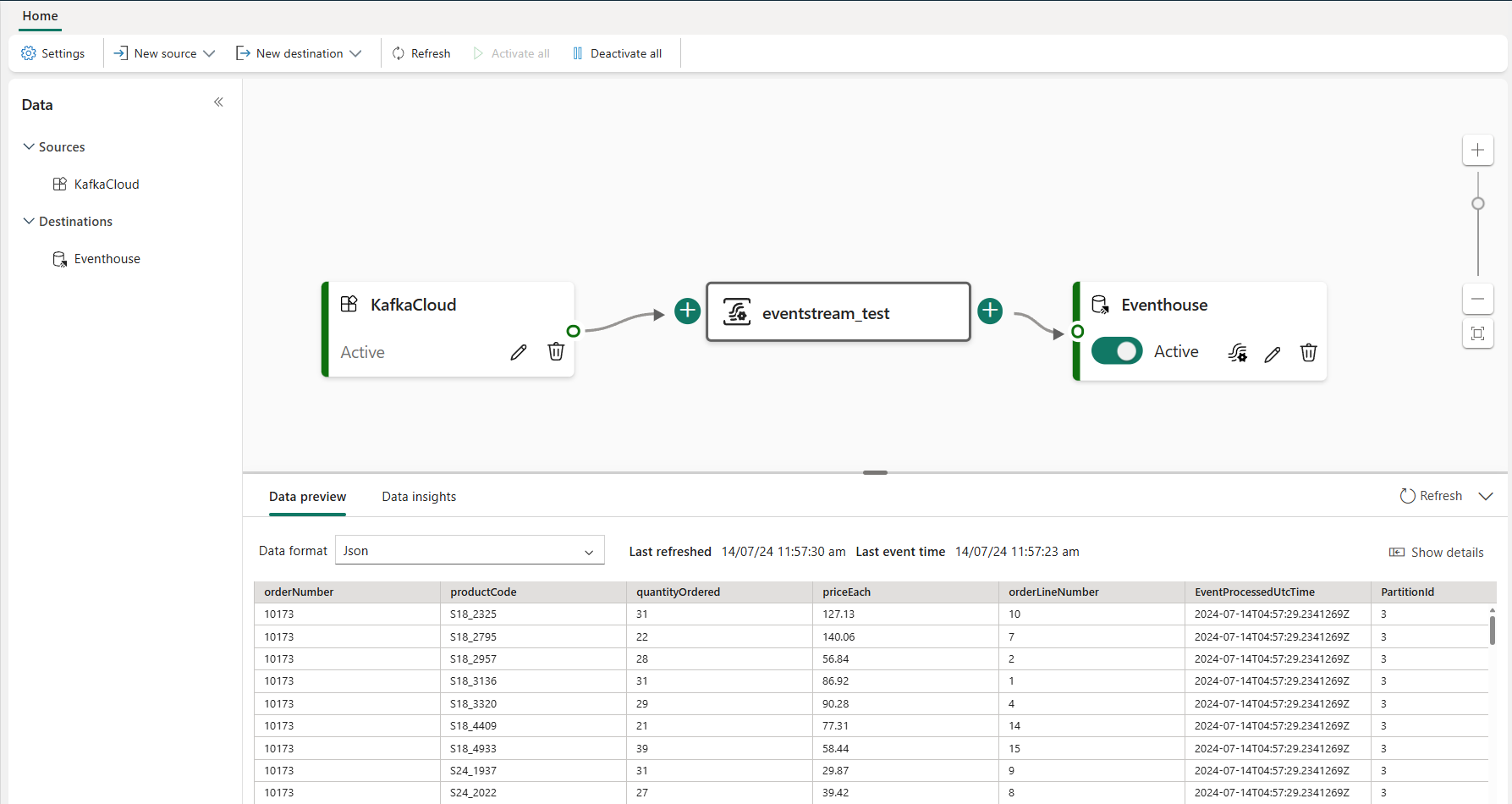
Hình 8.1: Dữ liệu được Ingest vào Cloud
Với những bước này, bạn có thể kiểm tra dữ liệu, xây dựng các dashboard và chuyển đổi dữ liệu một cách hiệu quả trong Microsoft Fabric sử dụng Eventstream. Để có hướng dẫn chi tiết hơn, hãy tham khảo tài nguyên và các hướng dẫn trên trang (Microsoft Fabric Vietnam | Facebook hoặc tài liệu chính thức của Microsoft Fabric.
Link source code:
DucAnhNTT/cdc-on-prem-to-fabric-RTA (github.com)
Link tài liệu tham khảo:
- Microsoft Fabric event streams overview – Microsoft Fabric | Microsoft Learn
- Real-Time Intelligence in Microsoft Fabric documentation – Microsoft Fabric | Microsoft Learn
- Realtime Change Data Capture Streaming | End to End Data Engineering Project (youtube.com)
- giraone/kafka-debezium-postgres: Setup for docker-compose based Confluent Kafka, Debezium Source Connector and Postgres (github.com)
Link sample database:
(MySQL Sample Database (mysqltutorial.org)
Viết bài: Nguyễn Trần Đức Anh





