


A.TỔNG QUAN DỰ ÁN
KPIM đang xây dựng giải pháp quản lý và phân tích dữ liệu bằng cách tải dữ liệu từ nguồn các nguồn database cục bộ lên Microsoft Fabric. Dữ liệu này bao gồm thông tin lịch sử hoạt động của giao dịch mua hàng, được tải lên và xử lý hoàn toàn trên nền tảng Microsoft Fabric.
Quá trình tải dữ liệu được thực hiện theo hai phương pháp: Full Load và Incremental Load:
- Full Load: Tải toàn bộ dữ liệu từ nguồn PostgreSQL lên Fabric, thường được sử dụng khi cần cập nhật toàn bộ hoặc làm mới dữ liệu trong hệ thống.
- Incremental Load: Tải những bản ghi mới hoặc thay đổi từ PostgreSQL có transaction_date lớn hơn ngày cuối cùng đã có trên Fabric, giúp tối ưu hóa quá trình tải và cập nhật dữ liệu mà không cần phải xử lý toàn bộ.
Việc sử dụng Microsoft Fabric, mang lại hiệu suất cao và khả năng mở rộng, thay thế các kiến công cụ truyền thống và đáp ứng nhu cầu hiện đại của doanh nghiệp. Qua dự án này, KPIM khai thác tối đa dịch vụ sẵn có của Fabric, giúp hiểu rõ quá trình triển khai hệ thống quản trị dữ liệu trên nền tảng đám mây tiên tiến.
B. CHI TIẾT GIẢI PHÁP
KPIM đã triển khai giải pháp sử dụng Microsoft Fabric, một nền tảng tích hợp giúp thực hiện các tác vụ từ quản trị đến phân tích dữ liệu và tạo báo cáo. Fabric có khả năng xử lý mạnh mẽ lượng dữ liệu lớn từ nhiều nguồn khác nhau, cung cấp các dịch vụ hỗ trợ đầy đủ các vai trò như Data Engineer, Data Analyst, và Data Scientist. Giải pháp này linh hoạt, có thể mở rộng và tùy chỉnh theo nhu cầu của doanh nghiệp. KPIM cũng cung cấp chuyên viên hỗ trợ để thay đổi, mở rộng quy trình xử lý và tạo báo cáo trên nền tảng này.
Tổng quan kiến trúc hệ thống sử dụng Microsoft Fabric trong dự án này:
- Data Source: Dữ liệu ban đầu được lấy từ PostgreSQL dưới local và tải lên Lakehouse
- Ingestion: Quá trình ingest được sử dụng các activity có sẵn trong Pipeline. Ngoài ra, sử dụng thêm notebook cho quá trình Incremental Load.
- Lakehouse: Là nơi lưu trữ chính trong hệ thống, Lakehouse kết hợp sức mạnh của Data Lake và Data Warehouse, cung cấp khả năng lưu trữ và xử lý dữ liệu lớn một cách linh hoạt và hiệu quả.
- Data Pipeline: Sử dụng các Data Pipeline tích hợp trong Fabric để tự động hóa quy trình ingest dữ liệu.
Kiến trúc này tập trung vào việc sử dụng Notebook, Data Pipeline và Lakehouse trong Microsoft Fabric, giúp quá trình xử lý dữ liệu linh hoạt và dễ mở rộng. Nhờ sự kết hợp này, doanh nghiệp có thể tối ưu hóa quy trình phân tích một cách hiệu quả.
C. CÁC BƯỚC THỰC HIỆN:
1. Cài đặt On-premises data gateway
On-premises data gateway là một ứng dụng được cài đặt trên hệ thống nội bộ cá nhân có tác dụng như là cầu nối truyền dữ liệu nhanh chóng và an toàn giữa on-premises data (dữ liệu lưu trữ ở nội bộ và không có trong đám mây) với một số dịch vụ đám mây của Microsoft.
Link cài đặt: https://learn.microsoft.com/en-us/data-integration/gateway/service-gateway-install
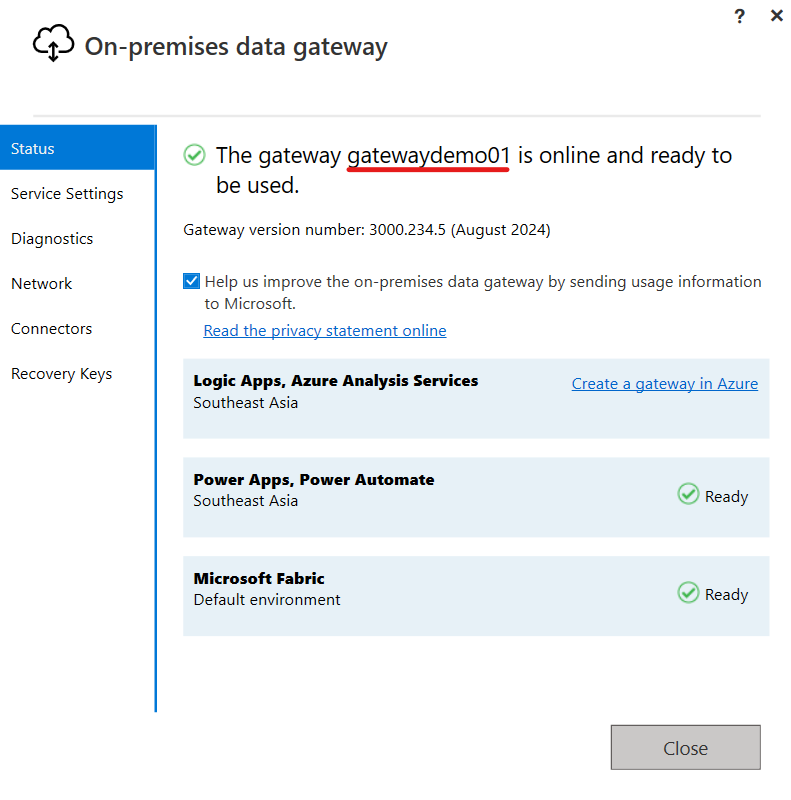
Sau khi tải về thành công, đăng nhập tài khoản và đặt tên cho gateway, ta được kết quả như hình dưới:
2. Cấu hình database cục bộ
- a. PostgreSQL
Khi một máy bên ngoài cố kết nối với PostgreSQL database, đầu tiên, nó phải qua được lớp xác thực ở mức hệ điều hành được cấu hình trong file pg_hba.conf. Các chính sách sẽ dựa trên các thông tin IP máy khách, tên người dùng database để quyết định xem máy khách có đi tiếp được hay không.
File pg_hba.conf được lưu trữ trong cùng với file postgresql.conf trong thư mục C:\Program Files\PostgreSQL\16\data.
- Cấu hình thêm các tham số trong file pg_hba.conf

- Cấu hình trong file postgresql.conf:

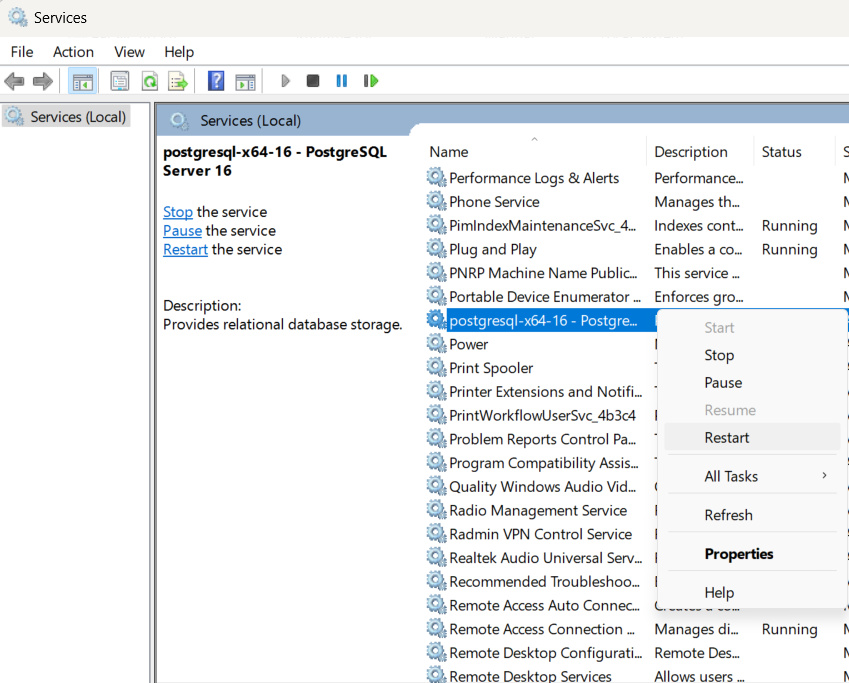
- Sau khi cấu hình sau, ta thực hiện reset lại service postgresql:
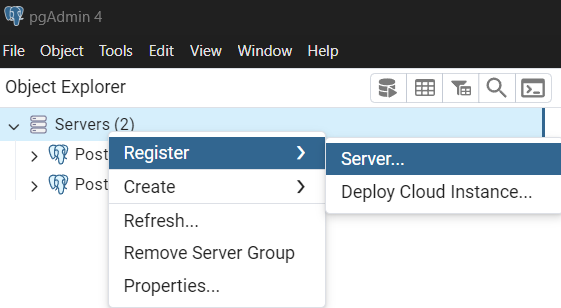
- Tạo một server mới bằng công cụ pgAdmin4 ( công cụ quản trị cơ sở dữ liệu front-end PostgreSQL):
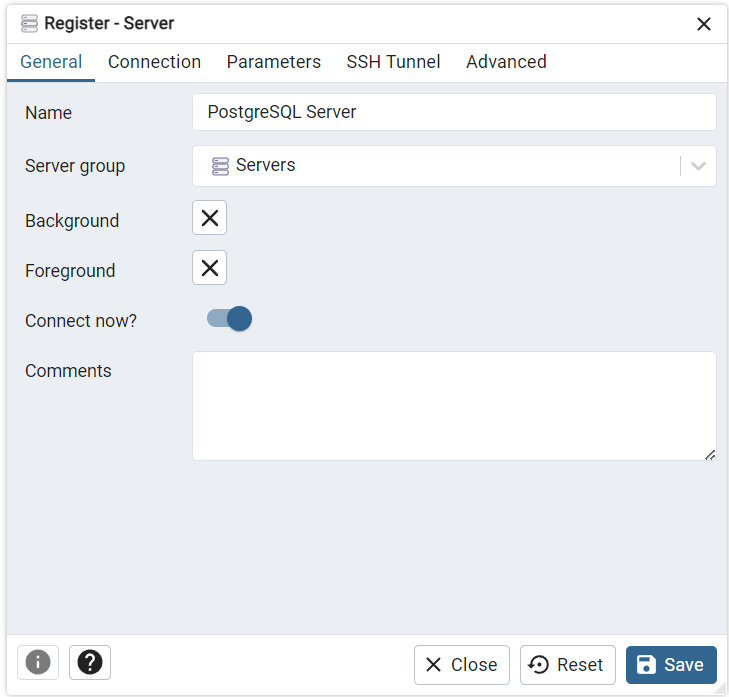
- Đặt tên cho server
- Cấu hình connection, host name ở đây để địa chỉ ip của máy tính cá nhân
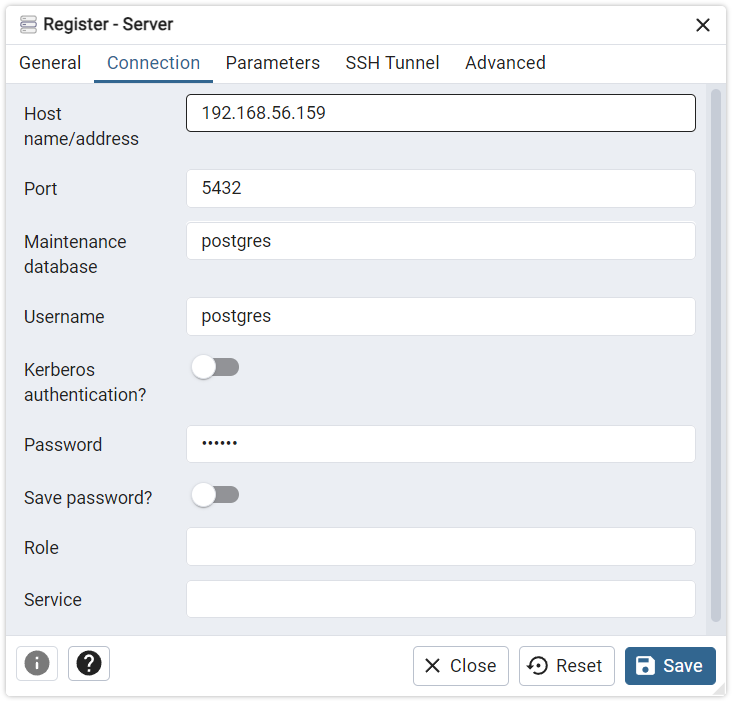
- Kết quả sau khi tạo thành công:
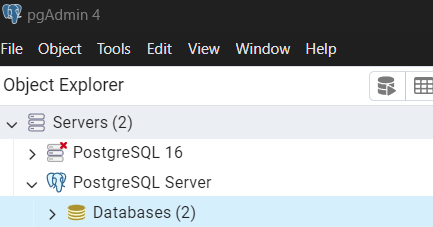
- b. MSSQL Server
Đối với MSSQL Server, ta cần tạo một tài khoản login vào server và trao quyền thực thi đến database cần sử dụng.
- Click phải vào Security –> New -> Login
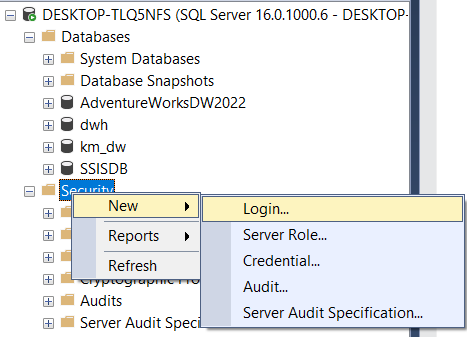 \
\
- Đặt tên login name, chọn SQL Server authentication
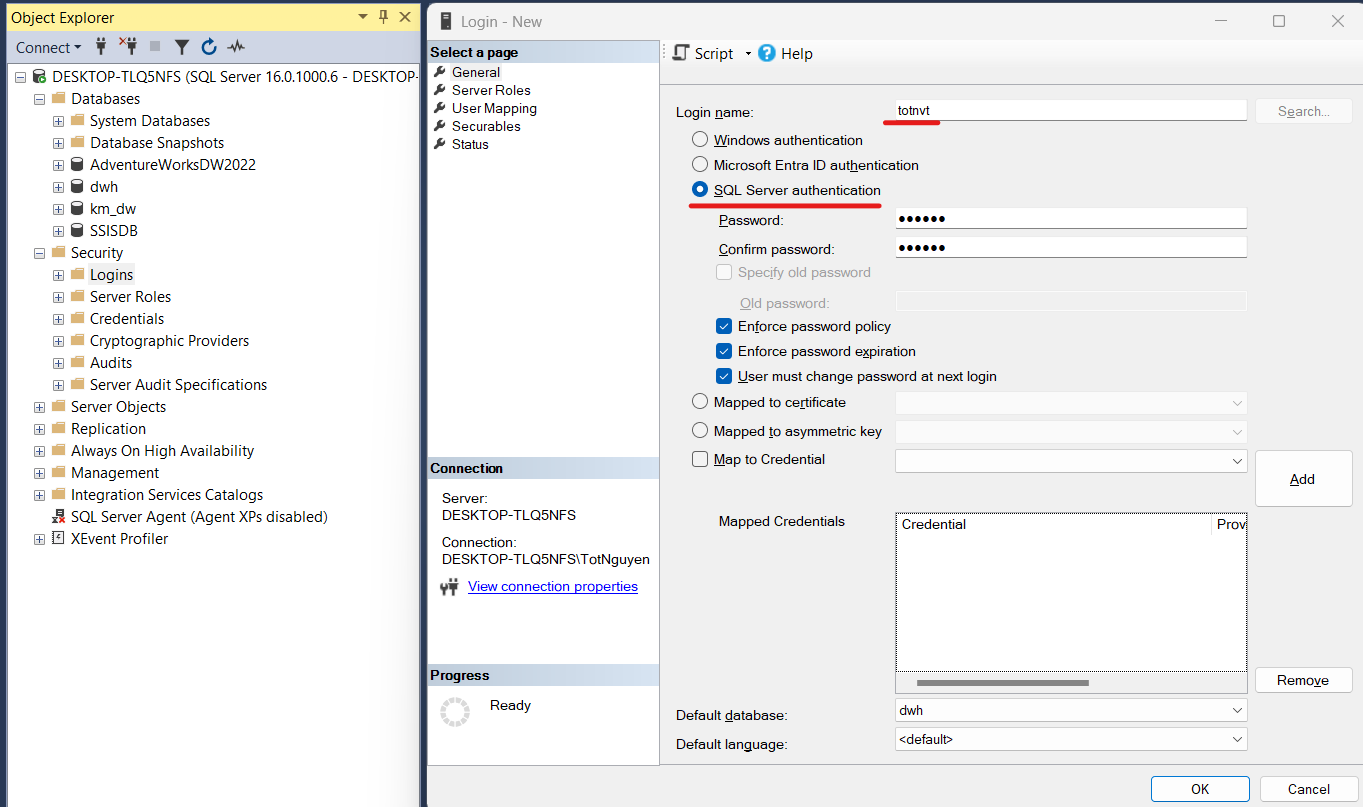
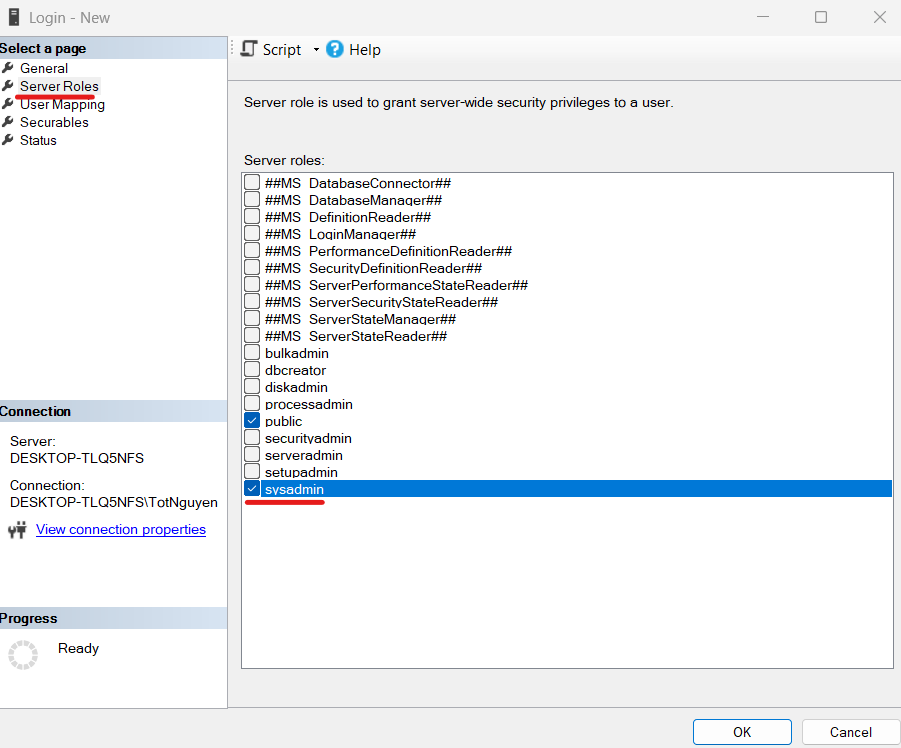
- Chuyển sang page Server Roles, cấp role cho tài khoản, tạm thời để role sysadmin
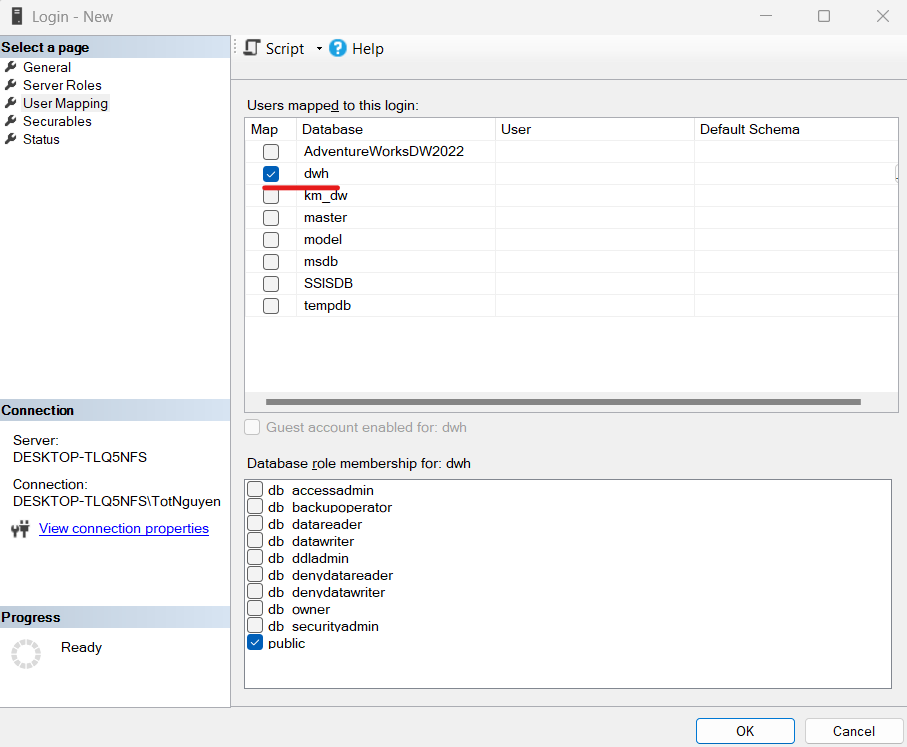
- Chuyển sang page User Mapping, chọn database cần sử dụng, sau đó click OK
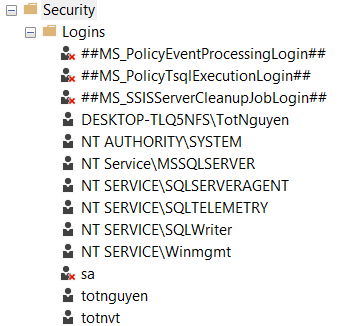
Kết quả sau khi tạo thành công
3. Tạo Connections and Gateways trên Fabric
- Trên trang home Fabric, click icon

, sau đó chọn Manage connections and gateways

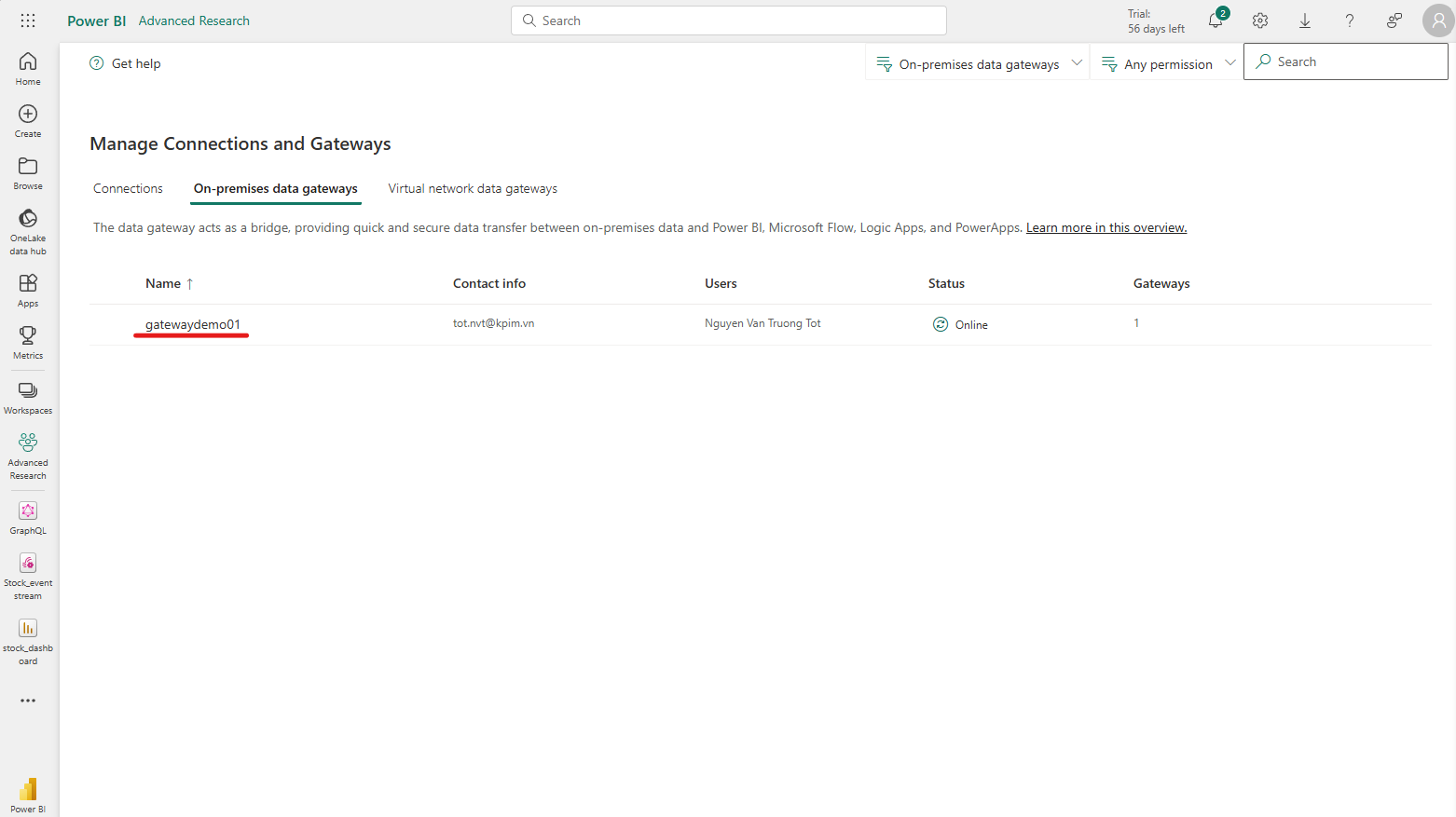
- Tại tab On-premises data gateways, ta thấy tên của gateway vừa tạo khi nãy đã có sẵn
- Chuyển qua tab Connections, ta click New để tạo một connection mới, chọn biểu tượng On-premises và điền các thông số để connect:

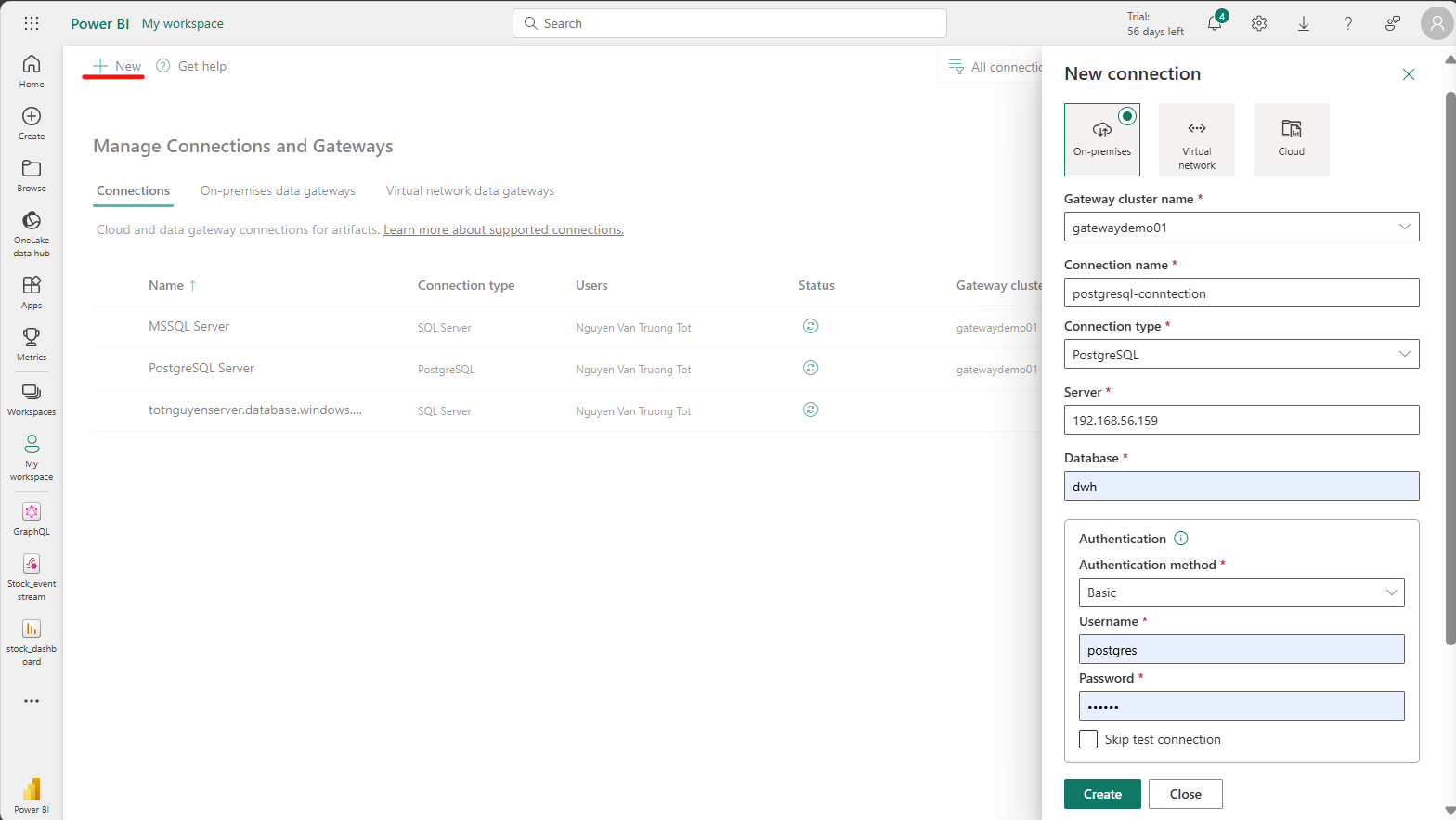
- Gateway cluster name: tên của cluster vừa được tạo bằng On-premises data gateway.
- Connection name: Đặt tên cho connection bất kì.
- Connect type: Ta lựa chọn PostgreSQL.
- Server: Tên server muốn kết nối tới.
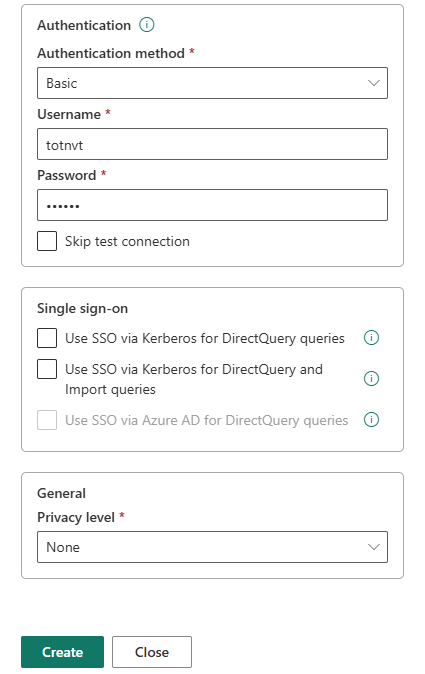
- Athentication: Nhập tài khoản và mật khẩu được tạo ở postgres local.
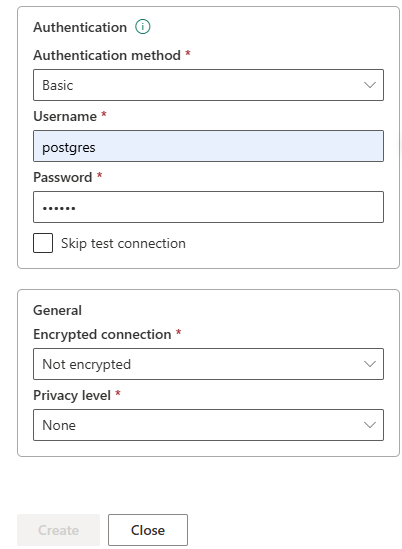
- Encrypted connection: chọn None.
- Privacy level: chọn None.
- Kết quả sau khi tạo thành công connection
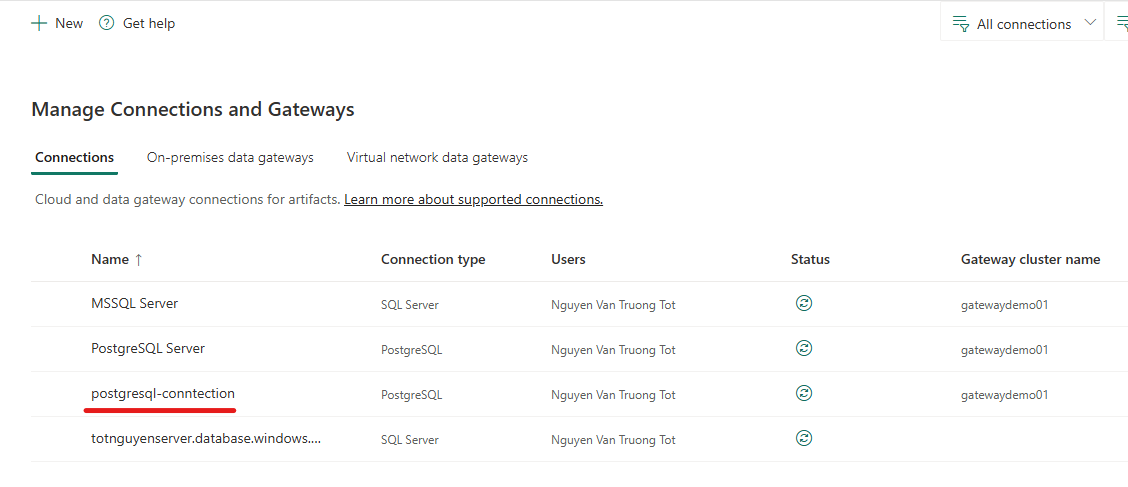
Tạo connection tương tự với SQL Server:
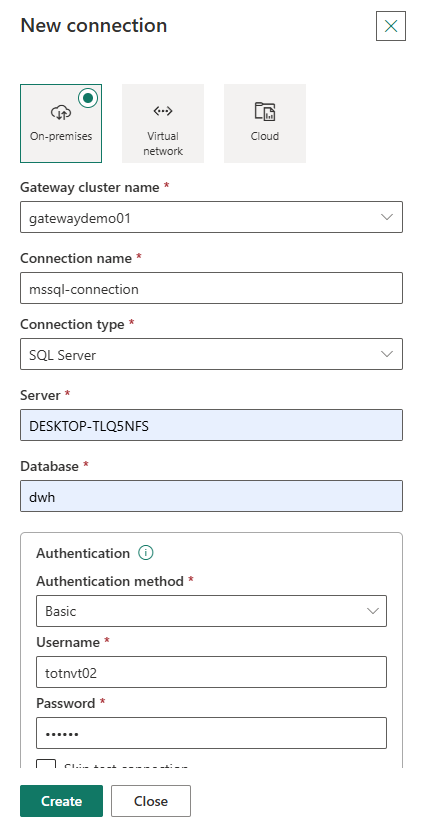
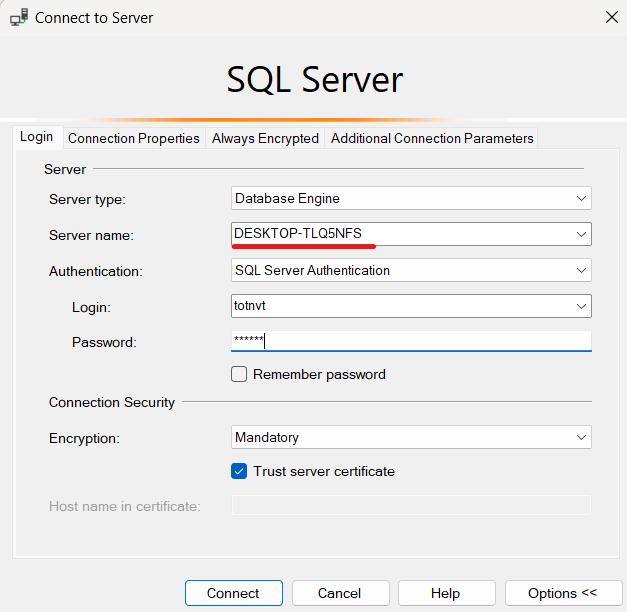
- Tại mục Server, lấy tên server name trên máy cục bộ khi login
* Các bước tiếp theo thực hiện mẫu cho PostgreSQL (SQL Server làm tương tự)
4. Tạo pipeline thực hiện ingest data
4.1 Full Load
- Tại workspace đang làm việc, click vào New để tạo một Data pipeline
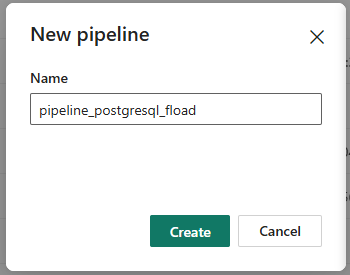
- Đặt tên cho pipeline
- Tại tab Activities, chọn Copy data -> Add to canvas
- Đặt tên cho activity vừa tạo
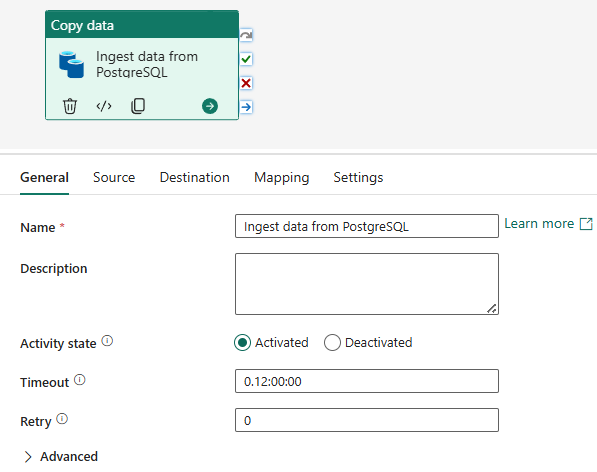
- Ở tab Source, chọn các thông tin để kết nối đến data source như sau:
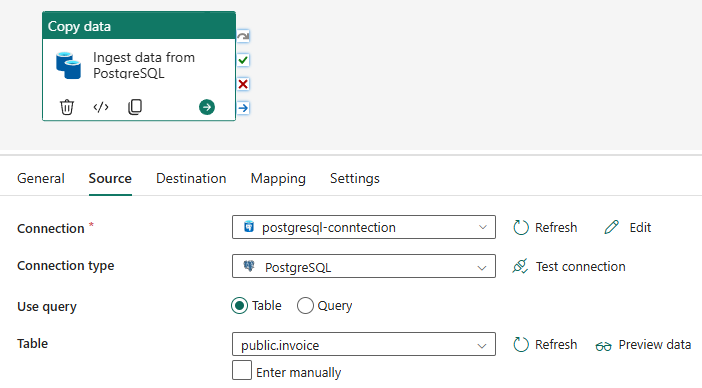
- Connection: chọn tên connection đã tạo khi nãy.
- Connection type: Chọn PostgreSQL.
- Use query: chọn Table.
- Table: chọn table đã tạo sẵn trong database Postgres
- Chuyển sang tab Destination, chọn các thông tin tương tự
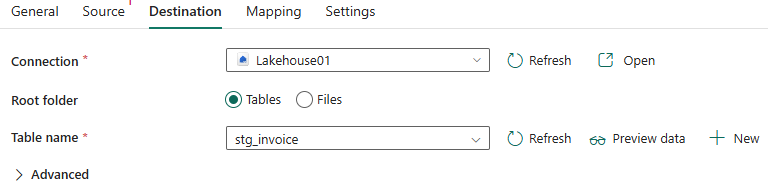
- Connection: chọn một object storage như lakehouse hoặc warehouse đã tạo trước.
- Root folder: chọn Tables
- Table name: chọn table đã có trong Lakehouse hoặc có thể chọn new để tạo mới table
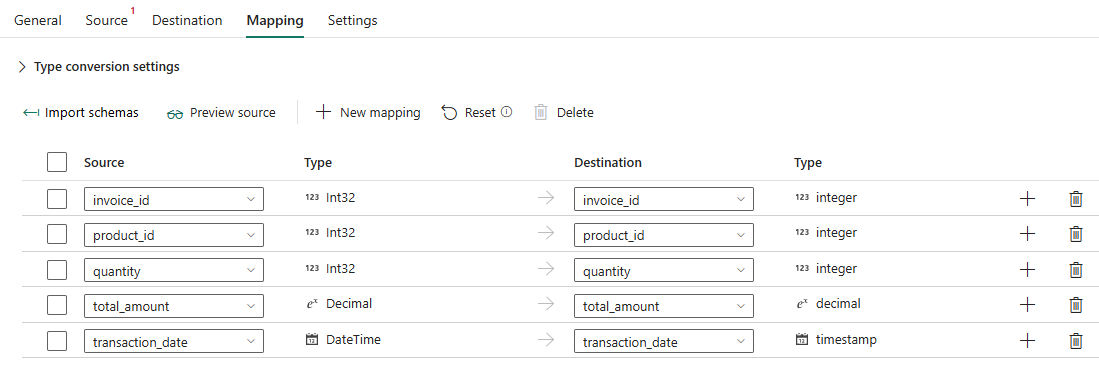
- Ở tab Mapping, chọn import schemas để mapping các trường ở data source với data destination
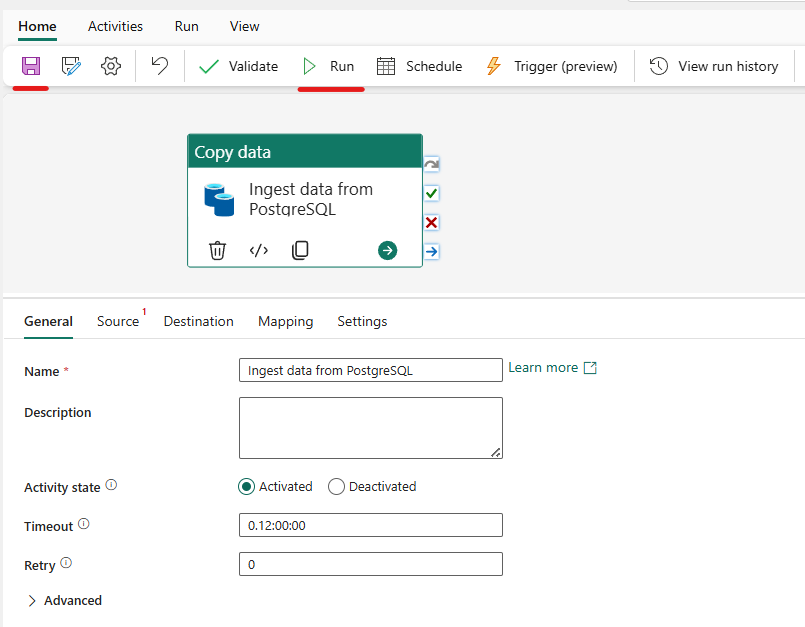
- Sau khi thiết lập xong, click vào icon save

để lưu pipeline và chọn Run để bắt đầu chạy pipeline
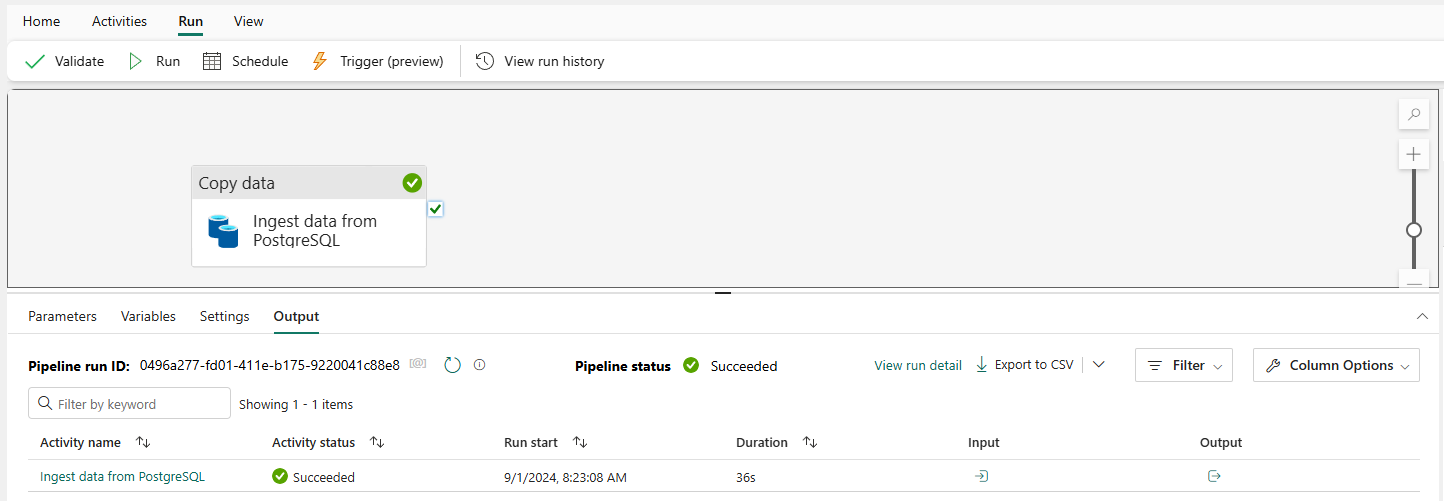
- Kết quả sau khi chạy thành công
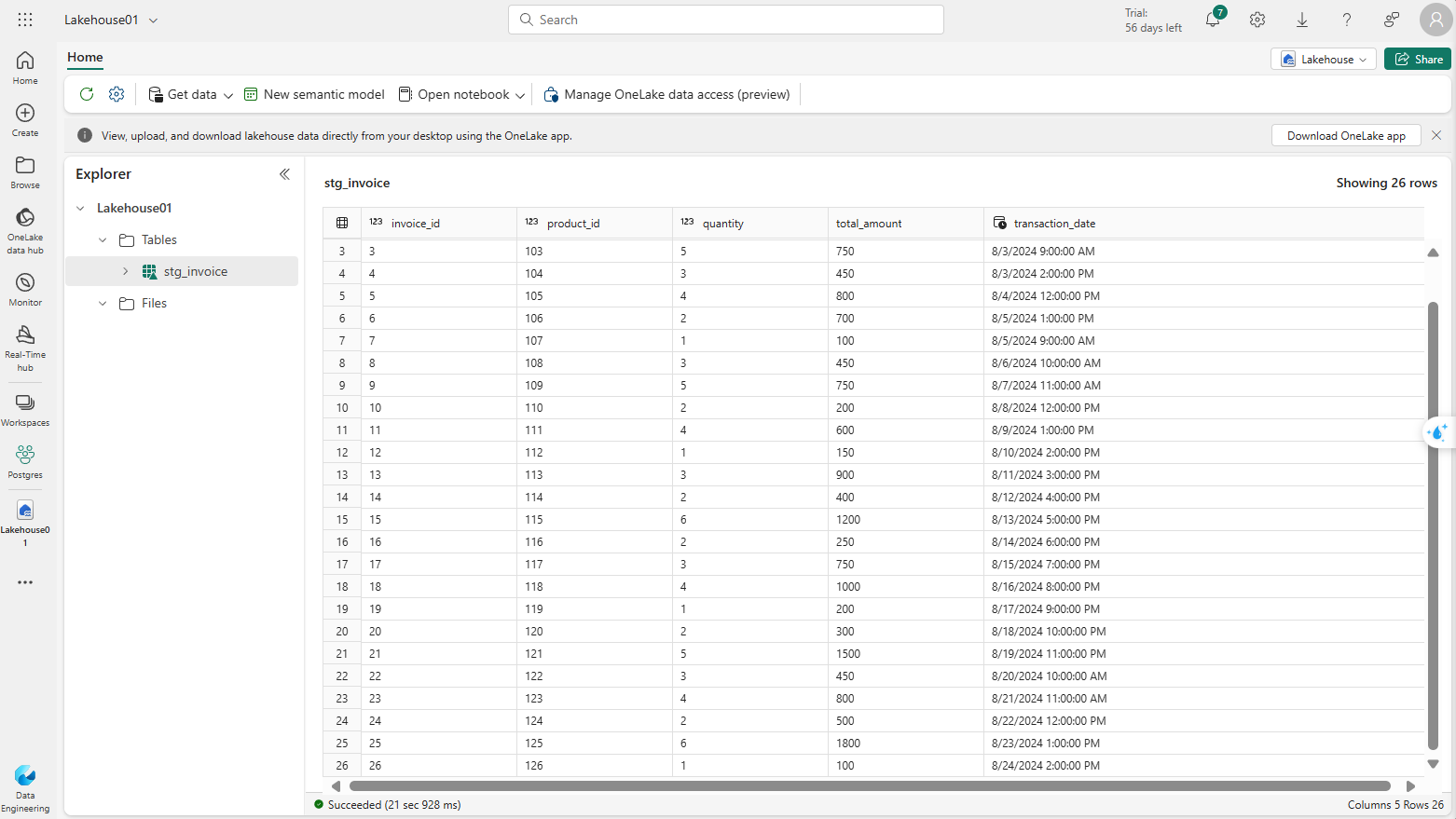
- Kiểm tra dữ liệu trong lakehouse sau khi chạy xong pipeline
4.2. Incremental Load
Incremental Load giúp chỉ tải những bản ghi mới từ data source mà có transaction_date lớn hơn transaction_date cuối cùng trong bảng data destination, thay vì phải tải toàn bộ dữ liệu. Các bước thực hiện như sau:
- Tại workspace đang làm việc, click New tạo một Notebook mới
- Đổi tên notebook ở góc trái trên cùng đồng thời thêm đoạn code mẫu như trong ảnh:
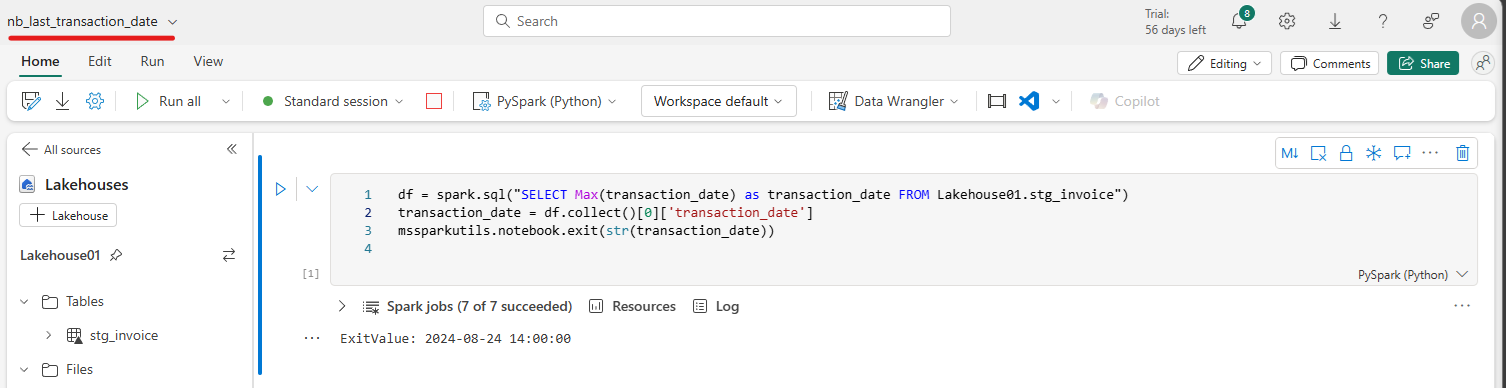
Mục đích của đoạn code trên sẽ giúp lấy ra được ngày giao dịch cuối cùng có trong bảng stg_invoice.
- Quay lại workspace làm việc, tạo một pipeline mới:
- Tạo một activity Notebook

- Sau khi tạo xong, chọn tab Setting ở notebook chọn các thông tin sau:
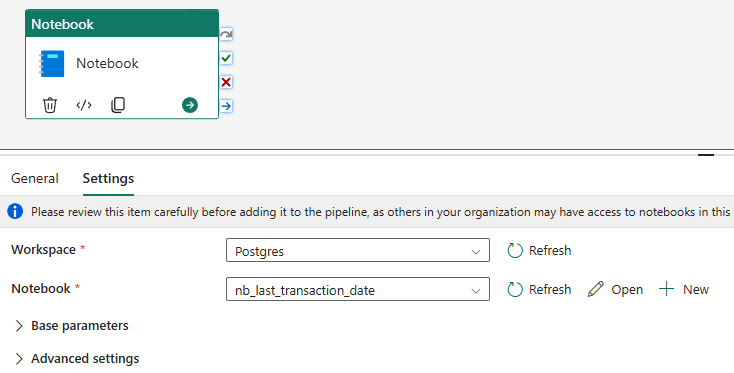
- Workspace: chọn Workspace đang làm việc.
- Notebook: chọn notebook vừa tạo ở bước trước
- Chuyển qua tab Activities, chọn Set variable, nối Notebook tạo trước đó với Set variable mới tạo bằng On success (icon tích xanh)
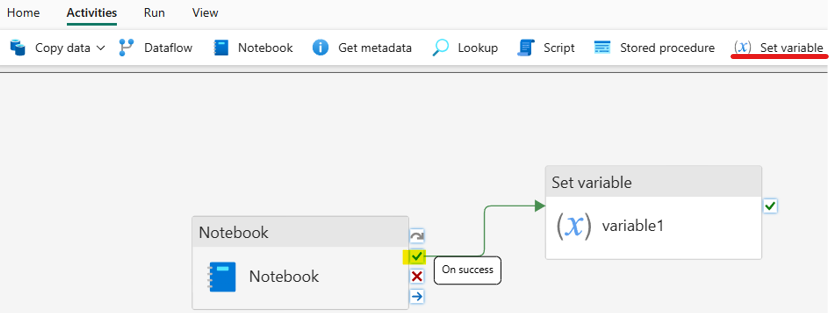
- Tại tab settings của Set variable, click New để đặt tên biến và thêm value như trong ảnh
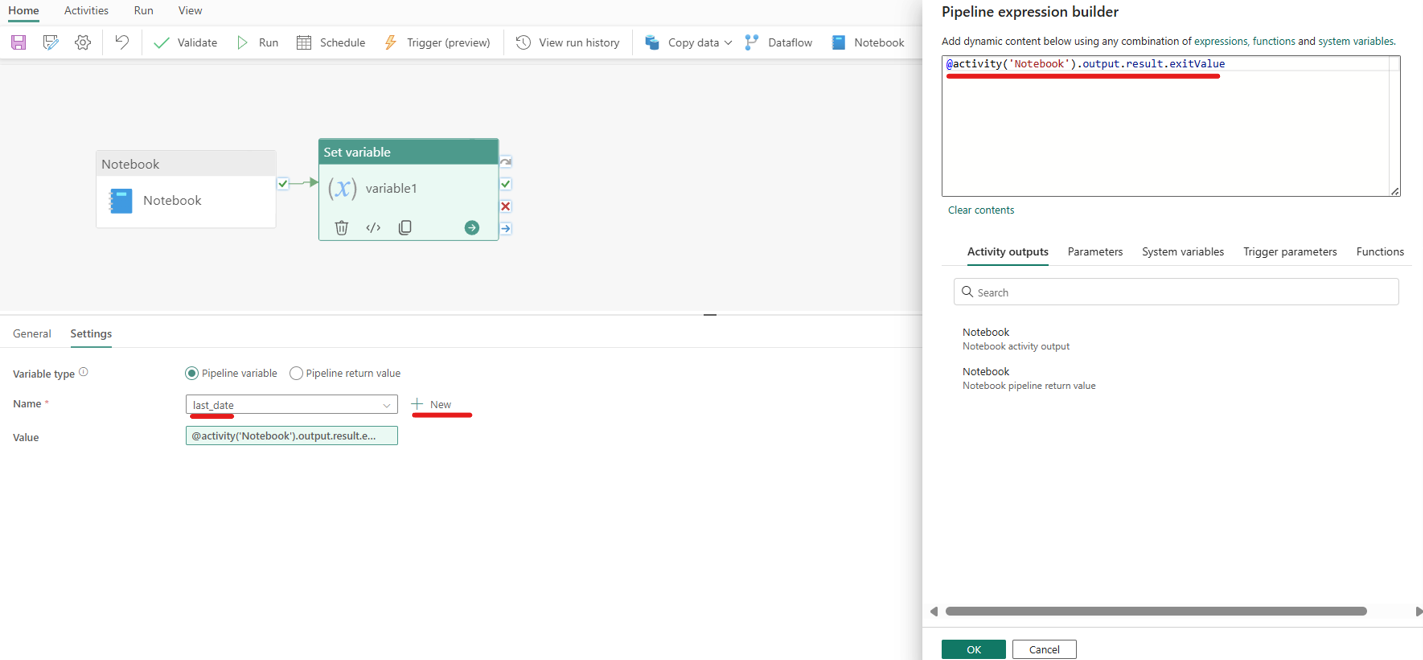
Mục đích của đoạn lệnh trên sẽ giúp lấy ra được giá trị trả về của activity Notebook ở bước trước, sau đó sẽ gán giá trị này vào biến last_date.
- Tạo activity Copy data, nối Set variable ở bước trước với Copy data bằng On success
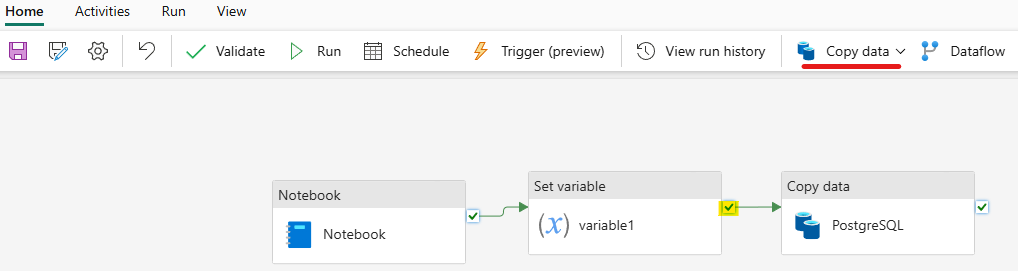
- Ở tab Source của Copy Data, chọn các thông tin như hình:
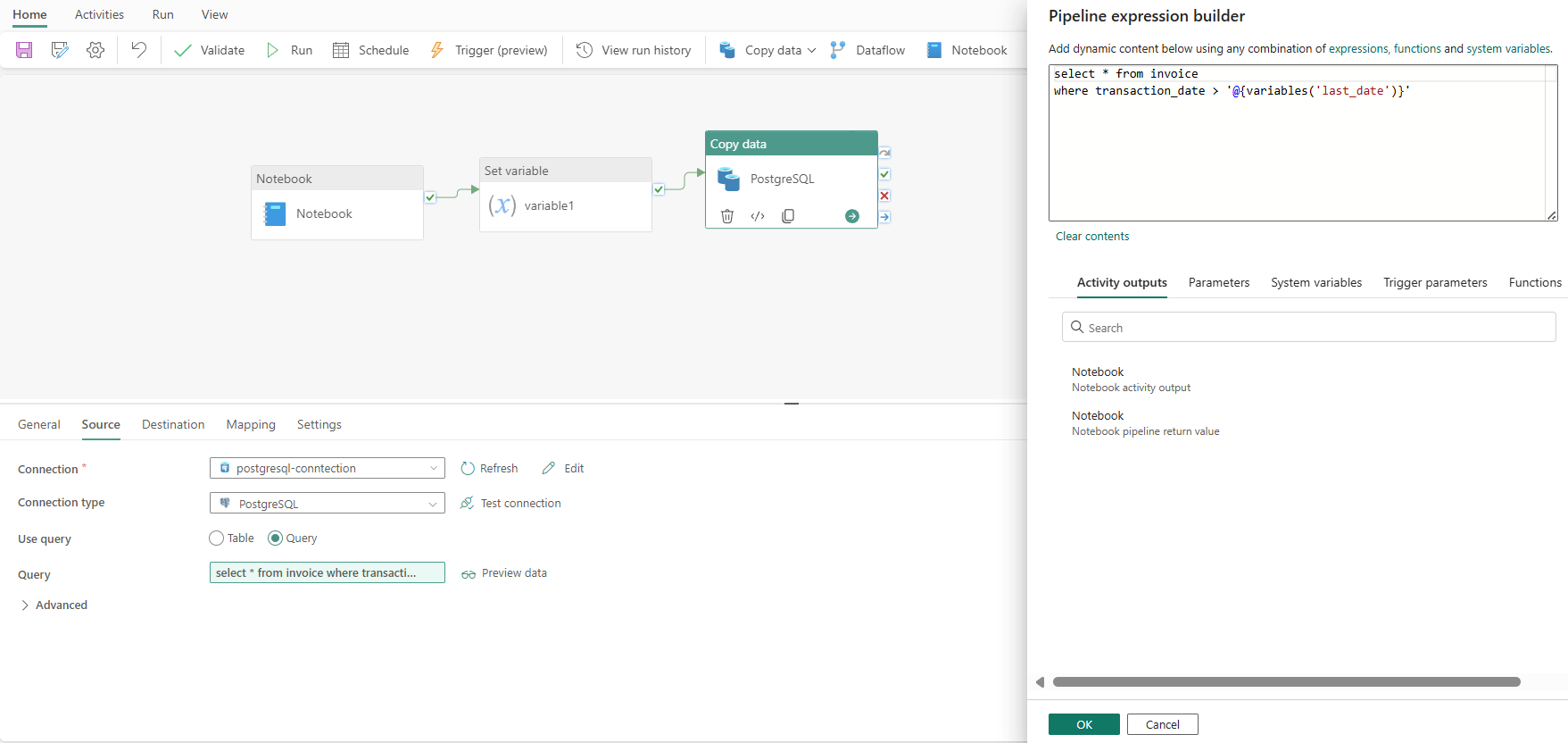
- Connection: chọn connection đã tạo các bước trước
- Connection type: chọn PostgrSQL
- Use query: Query
- Nội dung query:
select * from invoice
where transaction_date > ‘@{variables(‘last_date’)}’
Mục đích của đoạn code trên sẽ lấy về các bản ghi có transaction_date lớn hơn giá trị last_date đã được gán ở bước trước.
- Ở tab Destination, chọn tương tự như Full Load.
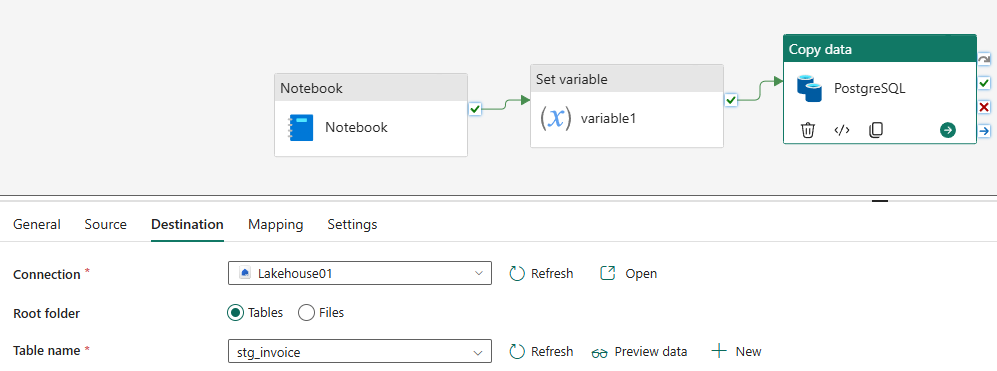
- Kết quả chạy pipeline:
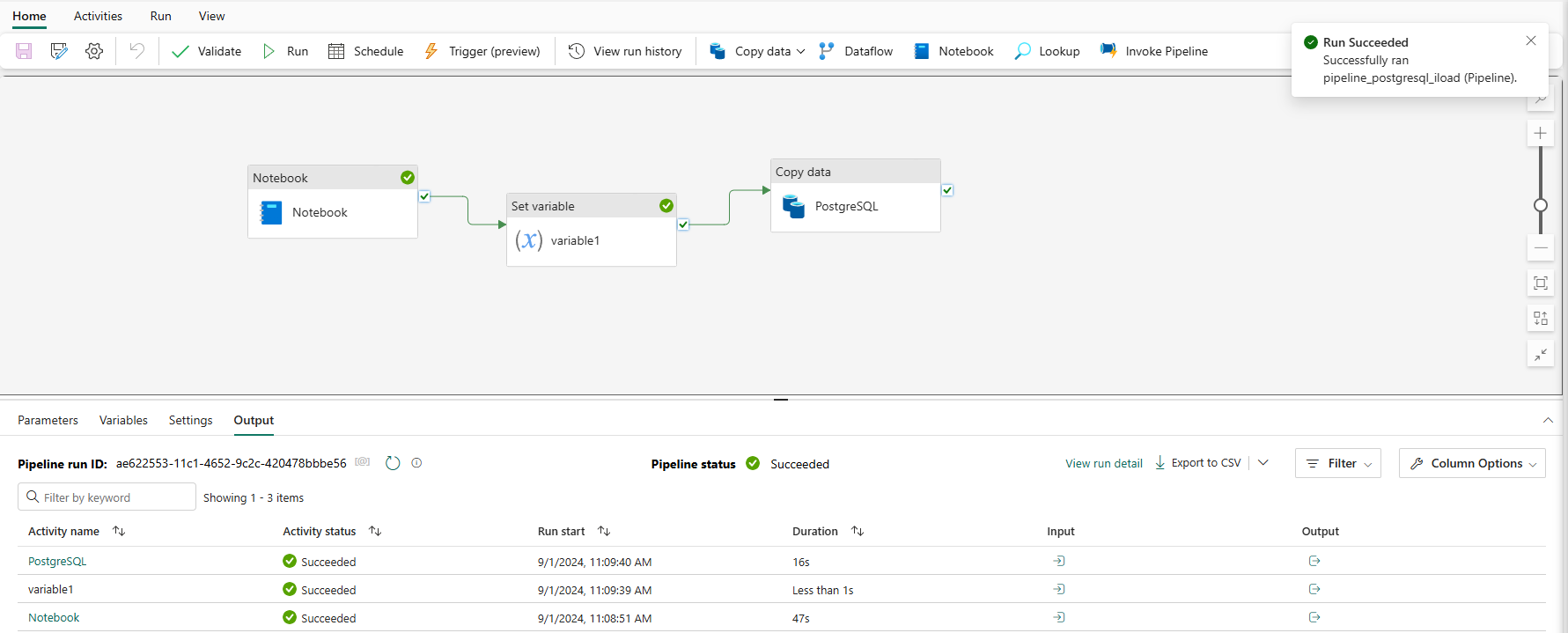
-
- Dữ liệu mới ở data source
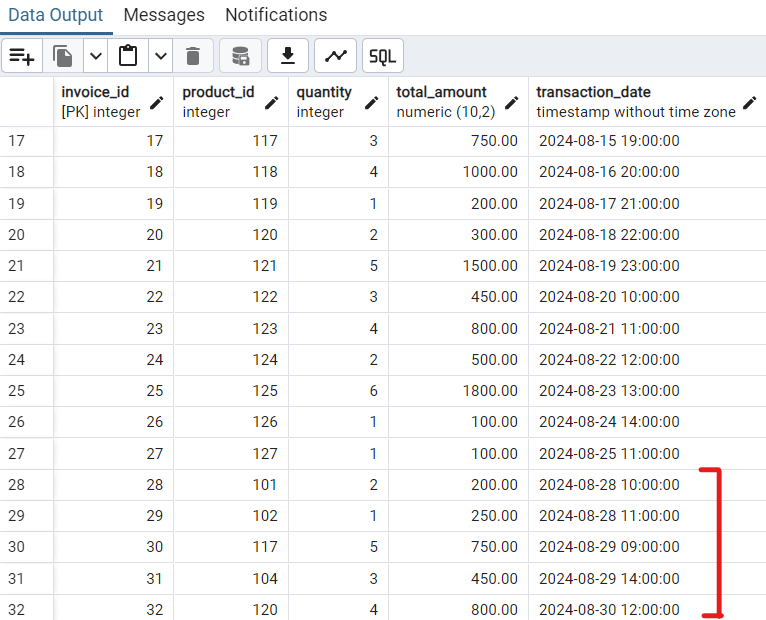
-
- Dữ liệu ở data destination trước khi chạy pipeline
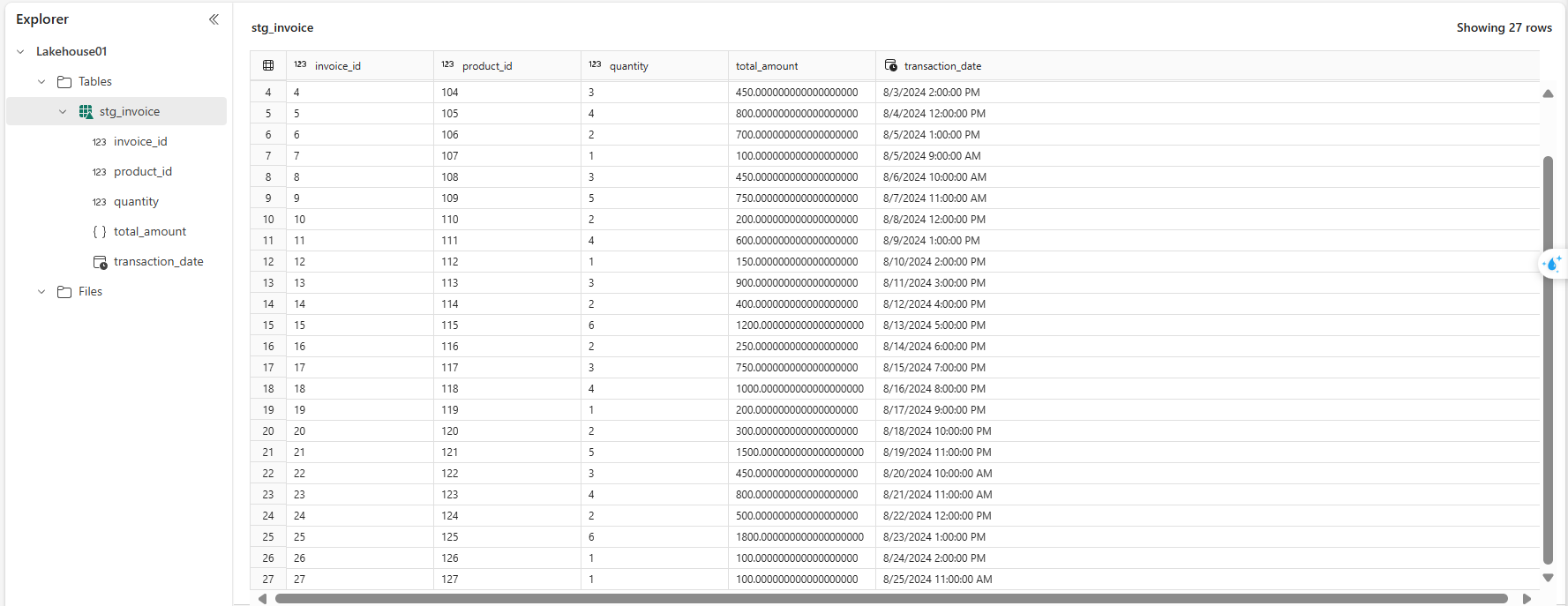
-
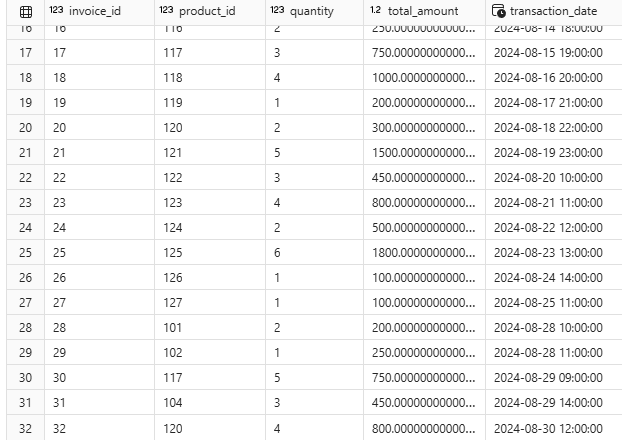
- Dữ liệu mới đã được tải vào data destination thành công
Viết bài: Nguyễn Văn Trường Tốt





